Update: Index-Fehler zu \(I_1\) (Danke, Martin!)
Update: auch hier habe mich mich noch strikter an die Lernziele gehalten. Zusätzlich dazu wurden noch ein paar Beispiele zu entscheidbaren und semi-entscheidbaren Funktionen eingepflegt um das Verständnis zu erleichtern, was mir hoffentlich gelungen ist 😉
Update 2: ich merke gerade, dass die Einträge zu lang sind. Selbst die Ladezeiten vom Chrome sind bei den Mathe-Symbolen für 10 Seiten exorbitant hoch. Ich habe daher beschlossen die Beiträge daher zu trennen.
Es gibt insg. drei vier Beiträge zur KE6.
- TIA: Rekursive und rekursiv-aufzählbare Mengen (Lernziele KE6, 1/4)
- TIA: Bild- und Projektionssatz (Lernziele KE6 2/4)
- TIA: Halte- Äquivalenz- und Korrektheitsproblem, Reduzierbarkeit, Satz von Rice (Lernziele KE6, 3/4)
- TIA: Gödel’scher Unvollständigkeitssatz (Lernziele KE6, 4/4)
Da die Lernziele im Skript etwas verstreut sind, kann es sein, dass ich etwas springen muss und nicht alles der Reihe nach abhake. Lasst euch davon nicht verwirren.
Dieser Eintrag befasst sich mit rekursiven und rekursiv-aufzählbaren Mengen und ihren Eigenschaften. Wir hatten bereits in den anderen Beiträgen viel mit Mengen zu tun. Ich werde die Erklärungen hier einfach Copy&Pasten, falls sie passen.
Lernziel 1 und 3
Definition rekursiver und rekursiv aufzählbarer Mengen von Zahlen und Wörtern
Zunächst einmal hilft es sich wie Bart bei den Simpsons 100x „Rekursiv = entscheidbar. Rekursiv aufzählbar = Semi entscheidbar“ wahlweise in das Parkett zu kratzen, die Wand zu tapezieren oder sich auf die Stirn tätowieren zu lassen. Nachdem das erledigt ist, wiederholt man das Gleiche dann noch mit der Definition (welche ich aus diesem Beitrag zur Entscheidbarkeit einfach Copy&Paste):
Eine Menge \( T \subseteq M\) ist entscheidbar/rekursiv wenn die charakteristische Funktion \(\chi_T: M \rightarrow \{0,1\}\) definiert durch
\(\chi_T(t)=\begin{cases} 1, & \mbox{ falls } t \in T \\ 0, & \mbox{ sonst}\end{cases}\)berechenbar ist (Achtung: sie muss berechenbar sein und nicht einfach nur existieren!).
Achtung: die charakteristische Funktion existiert immer und ist im Falle der Entscheidbarkeit auch immer total!
Dann nochmal für r.a.:
Eine Menge \(T\) ist semi-entscheidbar/rekursiv aufzählbar wenn die partielle charakteristische Funktion \(\chi^{‚}_T: M \rightarrow \{1\}\) definiert durch
\(\chi^{‚}_T(t)=\begin{cases} 1, & \mbox{ falls } t \in T \\ \perp, & \mbox{ sonst}\end{cases}\)berechenbar ist.
Achtung: hier existiert die charakteristische Funktion ebenfalls, sie ist aber nicht mehr total!
Manchmal sagt man auch, dass die „halbe“ charakteristische Funktion berechenbar ist. Oder wie im Skript ausgedrückt:
Eine Menge \(T\subseteq\mathbb{N}^k\) ist semi-entscheidbar/rekursiv aufzählbar wenn es eine partielle berechenbare Funktion \(f:\subseteq\mathbb{N}^k\rightarrow\mathbb{N}\) gibt mit \(T=Def(f)\).
Während sich die Definition für r.a. Mengen über die charakteristische Funktion noch erschließen mag, ist es bei dieser hier ein bisschen abstrakter.
Denkt euch eine Menge \(T\), wo Ihr nur entscheiden könnt ob ein Element zu dieser Menge gehört, aber nicht ob es nicht dazu gehört (sie ist also offensichtlich nur semi-entscheidbar). Und nun lasst Ihr die charakteristische Funktion \(f\) aus der 2. Definition auf jedem Element \(x\) dieser Menge \(A\) laufen.
Gehört das Element \(x\) zu dieser Menge \(T\), so ist die Ausgabe der Funktion \(f(x)=1\). Und das für jedes \(x\in{A}\), dass zur Menge \(T\) gehört. Gehört es nicht zur Menge \(T\), so rechnet die Funktion unendlich lange weiter. Damit sind alle positiv entschiedenen Elemente \(x\in A\) in der Menge \(T\) und ganz \(T\) damit der Definitionsbereich der Funktion \(f\), eben \(T=Def(f)\).
Wenn wir also entscheiden können ob ein Element in einer Menge ist oder nicht, ist die Menge rekursiv (z.B. bei der Entscheidung auf Primzahlen). Können wir nur positive (oder nur negative, aber nie beides) Entscheidungen treffen ob sich das Element in der Menge befindet (z.B. bei dem Halteproblem), dann ist die Menge nur rekursiv aufzählbar. Nicht vergessen: eine rekursive Menge ist auch rekursiv aufzählbar, aber eine rekursiv aufzählbare Menge nicht zwingend rekursiv.
Später kommen wir noch zu ein paar Beispielen für diese Mengen.
Eine weitere, wichtige Eigenschaft für rekursive Funktionen ist die folgende:
Eine unendliche Menge \(A\subseteq\mathbb{N}\) ist rekursiv, gwd. es eine wachsende, totale Funktion \(f\) gibt mit \(A = Bild(f)\). Wachsend bedeutet: \(f(n) < f(n+1)\)
Höre ich euch die Augenbrauen zusammenziehen? Müsst Ihr nicht. Es ist nicht schwer: was eine wachsende Funktion ist, wisst Ihr sicherlich: es ist eine Funktion, dessen Funktionswert bei der Eingabe vom Parameter \(n\) stets kleiner ist als bei der Eingabe von \(n+1\).
Beispiel: \(f(n)=n^2\)
Stellen wir für \(1\leq{n}\leq{5}\) mal die Funktionswerte zusammen:
\(f(1)=1,f(2)=4,f,(3)=9,f(4)=16,f(5)=25\)
Kein Funktionswert von \(f(n+1)\) ist kleiner als \(f(n)\). Damit ist sie wachsend.
Schaffen wir es also so eine Funktion \(f\) anzugeben, wo die Ausgabe (sog. Bildmenge) von \(f\) unsere komplette Menge \(A\) ist, so ist die Menge \(A\) entscheidbar/rekursiv.
Exkurs Nr. 2: weiterhin sind alle endlichen Mengen rekursiv/entscheidbar. Warum? Nehmen wir einfach eine beliebige, endliche Menge \(A\subseteq\mathbb{N}\). Egal welche Eigenschaften wir dieser Menge zuordnen, so können wir (theoretisch) einfach eine riesige charakteristische Funktion angeben, die für jedes Element entscheidet ob es zu \(A\) gehört oder nicht. Denn die Menge ist endlich.
Nun solltet Ihr einen kleinen Eindruck davon bekommen haben was entscheidbar/rekursiv und was semi-entscheidbar/rekursiv-aufzählbar ist.
Exkurs Nr. 3: Zusammenhang zu Wörtern
Der Zusammenhang zwischen Zahlen und Wörtern sollte nach der Standardnummerierung \(\sigma\) der Wörter über \(\Sigma^*\) sollte euch bereits klar sein. Denn alles, was wir über Mengen auf \(\mathbb{N}^k\) oder \(\mathbb{N}\) aufzählen, gilt selbstverständlich auch für Mengen über einem Alphabet \(\Sigma^{*}\).
Mittels Standardnummerierung können wir Worte aus einem Alphabet \(\Sigma\) nummerieren und umgekehrt. Das haben wir im Beitrag über \(\nu_\Sigma\) bereits erfolgreich getan.
Ebenfalls konnten wir Bandprogramme \(BP\) erfolgreich mit \(\nu_P\) nummerieren und entscheiden ob ein Wort über dem „Programmiersprachenalphabet“ \(\Omega^{*}\) ein Bandprogramm ist oder nicht. Damit ist die Menge der Bandprogramme \(BP\), der PASCAL-Programme und die Menge der \(WHILE\)-Programme entscheidbar/rekursiv.
Antwort zum Lernziel: eine Menge ist rekursiv/entscheidbar wenn ihre (volle) charakteristische Funktion berechenbar ist. Für eine nur semi-entscheidbare/rekursiv-aufzählbare Menge muss nur die „halbe“ charakteristische Funktion berechenbar sein.
Im ersten Fall können wir damit die vollständige Menge \(A\) entscheiden, d.h. ob ein Element zu dieser gehört oder nicht (formal ausgedrückt: \(x\in{A}\) und \(x\notin{A}\)). Im letzten Fall können wir nur positiv oder negativ entscheiden, aber nie beides gleichzeitig (formal ausgedrückt: \(x\in{A}\) oder \(x\notin{A}\), aber nicht beides gleichzeitig).
Eine Art Ausnahme bildet das Komplement einer semi-entscheidbaren Menge: können wir dieses ebenfalls semi-entscheiden, so ist die komplette Menge entscheidbar. Denn damit haben wir im Endeffekt die positive und negative Antwort, d.h. die „volle“ charakteristische Funktion berechnet.
Lernziel 4
Abschlusseigenschaften rekursiver und rekursiv aufzählbarer Mengen
Im Skript werden die folgenden, abschließenden Eigenschaften von rekursiven/entscheidbaren Mengen genannt:
1. \(A_1, A_2 \subseteq \mathbb{N}^k\) rekursiv. Damit ist auch \(\mathbb{N}^k\setminus A_1, A_1 \cup A_2\) und \(A_1 \cap A_2\) rekursiv.
2. Sei \(A \subseteq \mathbb{N}\) rekursiv, sei \(f \in R^{(1)}\). Dann ist \(f^{-1}[A]\) rekursiv.
3. Sei \(A \subseteq \mathbb{N}^k\), dann gilt: \(A\) rekursiv \(\Longleftrightarrow \pi^{(k)}[A]\) rekursiv.
Die 1. Eigenschaft ist soweit deutlich: \(A_1\) und \(A_2\) sind Teilmengen aus \(\mathbb{N}^k\) mit eben der Stelligkeit \(k\). Restmenge, Vereinigungsmenge und Schnittmenge sind damit auch rekursiv.
Eigenschaft Nr. 2 ist etwas aufwändiger wenn Ihr mit der Schreibweise nicht vertraut seid und (wie ich) Abschnitt 1.3 überlesen habt. Daher hier zur Auffrischung nochmal. Einer Korrespondenz wird eine Funktion \(f\) zugeordnet, die Mengen transformiert. Die Umkehrfunktion davon \(f^{-1}[A]\). Wenn die Menge \(A\) nun rekursiv ist und es eine totale Funktion \(f\) gibt, so ist auch die Umkehrfunktion rekursiv.
Durch die Cantorfunktion aus Eigenschaft Nr. 3 können wir uns bei unseren Untersuchungen auf die rekursiven Teilmengen von \(\mathbb{N}\) beschränken. Wir erinnern uns: wie können mit dieser Funktion \(\pi\) beliebige \(k\)-stellige Tupel auf eine natürliche Zahl aus \(\mathbb{N}\) abbilden. Wer sich nicht dran erinnert, sollte sich nochmal den Beitrag zu Gemüte führen.
Wir haben damit sichergestellt, dass Operatoren die rekursiven Mengen auch wieder in rekursive Mengen transformieren.
Anschließend folgen die Abschlusseigenschaften der rekursiv aufzählbaren/semi-entscheidbaren (r.a.) Mengen:
1. \(A_1, A_2 \subseteq \mathbb{N}^k\) r.a. Damit ist auch \(A_1\cup A_2\) und \(A_1 \cap A_2\) r.a.
2. Sei \(A \subseteq \mathbb{N}\) r.a., sei \(f \in P^{(k)}\). Dann ist \(f^{-1}[A]\) r.a.
3. Sei \(A \subseteq \mathbb{N}^k\), dann gilt: \(A\) r.a. \(\Longleftrightarrow \pi^{(k)}[A]\) r.a.
Die Erläuterung erfolgt analog zu rekursiven Mengen. Bitte aber beachten, dass wir nun auf den partiellen, mehrstelligen, berechenbaren Funktionen \(P^{(k)}\) arbeiten und nicht mehr auf den totalen \(R^{k}\).
Zusammenfassend zitiere ich aus der Wikipedia für die rekursiven/entscheidbaren und rekursiv-aufzählbare/semi-entscheidbare Mengen:
- Jede entscheidbare Menge ist rekursiv aufzählbar, aber es gibt rekursiv aufzählbare Mengen, die nicht entscheidbar sind.
- Eine Menge ist genau dann entscheidbar, wenn sie und ihr Komplement rekursiv aufzählbar sind.
- Jede endliche Menge ist rekursiv aufzählbar.
- Jede rekursiv aufzählbare Menge ist abzählbar, aber nicht alle abzählbaren Mengen sind rekursiv aufzählbar.
- Jede unendliche rekursiv aufzählbare Menge besitzt Teilmengen, die nicht rekursiv aufzählbar sind.
- Der Schnitt von endlich vielen rekursiv aufzählbaren Mengen ist rekursiv aufzählbar; die Vereinigung einer rekursiv aufzählbaren Menge von rekursiv aufzählbaren Mengen ist rekursiv aufzählbar. Es gibt rekursiv aufzählbaren Mengen, deren Komplement nicht rekursiv aufzählbar ist.
Antwort zum Lernziel: die entscheidbaren Mengen sind abgeschlossen bzgl. Komplement, Schnitt und Vereinigung. Die semi-entscheidbaren mengen jedoch nur bzgl. Schnitt und Vereinigung, das Komplement ist nicht semi-entscheidbar (wäre es das, so wäre die Menge vollständig entscheidbar. Siehe vorheriges Lernziel).
Lernziel 2a
Nachweis der Rekursivität/Entscheidbarkeit von Mengen
Was tun wir um die Rekursivität von Mengen zu beweisen? Wir geben ein Flussdiagramm einer verallgemeinerten Registermaschine an, welches die charakteristische Funktion für die zu untersuchende Menge berechnet. Wir entscheiden nun wirklich ob ein Element in der rekursiven Menge ist oder nicht. Dazu verwenden wir alle bereits als berechenbar bewiesenen Funktionen. Mehr nicht.
Hilfreich ist hierfür die Auflistung der berechenbaren Funktionen aus Satz 3.2.5:
- Nullfunktion
- Nachfolger- und Vorgängerfunktion
- Projektion
- konstante Funktion
- Summe
- arithmetische Differenz
- Produkt
- Quotient und Rest
- Exponentation
- Wurzel
- max/min
- Primzahltest und \(x\)-te Primzahl
Könnt ihr alle für euer Flussdiagramm benutzen 😉
Beispiel? Sicher: \(T=\{x\in\mathbb{N}\mid x\text{ ist Primzahl}\}\)
Die dazu notwendige, charakteristische Funktion ist:
\(\chi_T(x)=\begin{cases} 1, & \mbox{ falls } x\text{ Primzahl} \\ 0, & \mbox{ sonst}\end{cases}\)
Test auf Primzahl: Für alle \(y\) mit \(1<y<x\) wird getestet ob es bei der Division von \(x\) durch \(y\) einen Rest gibt. Gibt es bei einem \(y\) keinen Rest, so ist es keine Primzahl (dann ist \(y\) nämlich ein legitimer Teiler von \(x\)).
Damit können wir für jedes \(x\in\mathbb{N}\) entscheiden ob es eine Primzahl ist oder nicht. Das Flussdiagramm für den Test dürft Ihr selbst angeben 😉
Ein weiteres Beispiel wäre z.B. der Test auf die Goldbach-Eigenschaft einer Zahl.
Antwort zum Lernziel: um zu zeigen, dass eine Menge entscheidbar/rekursiv ist, muss die (volle) charakteristische Funktion berechenbar sein.
Dazu gibt man das Flussdiagramm einer verallgemeinerten Maschine (wenn man streng ist, muss man für jeden verallgemeinerten Test seine Berechenbarkeit ebenfalls nachweisen und letztendlich seine Maschine auf die drei Grundoperationen Addition/Subtraktion von \(1\) und Test auf \(0\) zurückführen) an, die diese berechnet und in jedem Fall mit einem Ergebnis hält.
Lernziel 2b
Nachweis der rekursiven Aufzählbarkeit/Semi-entscheidbarkeit von Mengen
Auch hier ist es nicht allzu schwierig. Jede rekursiv aufzählbare (semi entscheidbare) Menge ist auch gleichzeitig aufzählbar und jede aufzählbare Menge ist auch rekursiv aufzählbar (semi entscheidbar). Daher müssen wir es nur schaffen, die Elemente der Menge irgendwie aufzuzählen. Man macht sich leicht klar, dass der Definitionsbereich und Wertebereich von berechenbaren Funktionen rekursiv aufzählbar ist.
Aber was ist mit \(n\)-Tupeln? Die sind dank Cantor’schen Tupelfunktion auf ein Element reduzierbar, d.h. wir können \(n\)-Tupel auf einelementige Mengen reduzieren und unseren Schabernack mit ihnen treiben.
Wird also gefragt, ob eine Menge rekursiv aufzählbar ist, so geben wir einfach eine charakteristische Funktion an, die die Eigenschaft der Menge nur positiv (oder nur negativ) beantwortet. Für die gegensätzliche Antwort muss unsere charakteristische Funktion (im Gegensatz zur vollen charakteristischen Funktion für entscheidbare Mengen) nicht halten, Hauptsache sie sagt uns zuverlässig eine der beiden Antworten. Ein gutes Beispiel ist das Post’sche Korrespondenzproblem.
Beispiel: Post’sches Korrespondenzproblem
Das Post’sche Korrespondenzproblem beschreibt das Problem bei Wortpaaren \((x_1,y_1),…,(x_n,y_n)\) eine Folge \(i_1,…,i_k\) mit der Eigenschaft: \(x_{i_1}x_{i_2}…x_{i_k} = y_{i_1}y_{i_2}…y_{i_k}\) zu finden. Ist natürlich wieder etwas abstrakt, aber probieren wir das mal an einem Beispielproblem:
Beispielproblem \(P=((01,1),(0,000),(01000,01))\)
\(P\) nennt man Problemfall oder Instanz.
Fragestellung: gibt es eine Lösung (d.h. eine Folge von Indices) \(I\) zum Problemfall \(P\)? Wenn ja, ist die Folge eine Lösung von \(P\).
Wir müssen hier also eine Kombination von zwei Wortkombinationen \(\omega_1 = \omega_2\) finden und die folgenden Regeln einhalten:
- \(\omega_1\) darf nur aus den 1. Elementen der 3 Wortpaare bestehen: \(01,0\) und \(01000\).
- Das Wort \(\omega_2\) darf nur aus den 2. Elementen der 3 Wortpaare bestehen: \(1,000\) und \(01\).
- Die Wortkombinationen \(\omega_1\) und \(\omega_2\) dürfen beliebig lang sein.
Was Indices sind, ist euch klar? Nein, keine Sorge. Kommt gleich. Es liegt also an unserer Kombinationsgabe eine passende Index-Kombination zu finden, so dass am Ende gilt: \(\omega_1=\omega_2\).
Eine mögliche Lösung wäre \(\omega_1 = 01000\mid{0}\mid{0}\mid{01}\) und \(\omega_2=01\mid{000}\mid{000}\mid{1}\). (die \(\mid\) sind nur optische Trennzeichen damit Ihr die Elemente identifizieren könnt aus denen die Worte bestehen).
Die zugehörigen Indices wären: \(I_1=(3,2,2,1)\). Damit ist \(I_1\) eine Lösung für \(P\) und \(P\) damit gelöst.
Die Indices sind nichts weiter als die Nummer des Tupels, dass zur Bildung herangezogen wird. Da wir für das erste Wort \(\omega_1\) nur die ersten und für das zweite Wort \(\omega_2\) nur die zweiten Elemente aus den Tupeln benutzen dürfen, reicht uns als Angabe einfach nur die Nummer des Tupels.
Würden wir z.B. die folgende Lösung austesten wollen: \(I_2=(2,3,1,1)\), so wären die Worte \(\omega_1\) und \(\omega_2\):
\(\omega_1=0\mid{01000}\mid{01}\mid{01}\) und
\(\omega_2=000\mid{01}\mid{1}\mid{1}\)
Da \(\omega_1\neq\omega_2\), ist die mögliche Lösung \(I_2\) falsch und \(P\) noch nicht gelöst. Aber was nicht ist, kann ja noch werden!
Um zu zeigen, dass die Menge dieser Worttupel rekursiv aufzählbar/semi entscheidbar ist brauchen wir nur zu zeigen, dass die Menge der Definitionsbereich einer partiellen Funktion ist und die dazugehörige Maschine anzugeben, welche die charakteristische Funktion für diese Menge berechnet und in jedem Fall mit einer \(1\) terminiert wenn das Element in der Menge ist oder nicht terminiert, wenn es das nicht ist.
Die charakteristische Funktion für dieses Problem wäre:
\(\chi^{‚}_P(I)=\begin{cases} 1, & \mbox{ falls }\omega_1=\omega_2 \\ \perp, & \mbox{ sonst}\end{cases}\)
Das Flussdiagramm beschreibe ich hier ebenfalls am besten in Pseudocode:
- Setze \(n=1\)
- Fange mit einer Indexfolge \(I\) der Länge \(n\) an
- Erstelle durch den Index \(I\) die Worte \(\omega_1\) und \(\omega_2\) mit Länge \(n\)
- Prüfe ob \(\omega_1=\omega_2\).
Wenn ja, so ist eine Lösung für \(P\) gefunden: HALT!
Wenn nein, setze \(n=n+1\) und gehe zu Punkt 2.
Wie man am Pseudocode gut erkennen kann, kann man zu einer gegebenen Probleminstanz \(P\) eine Lösung durch systematisches ausprobieren finden.
Es ist damit sichergestellt, dass wir so tatsächlich eine korrekte Lösung finden wenn es eine gibt. Und wenn nicht? Da die Länge der Indexfolge unendlich ist und unsere Worte somit unendlich lang werden, kann es sein, dass wir niemals anhalten. Im ungünstigsten Fall läuft unser Programm für eine Kombination also ewig.
So können wir nur schlussfolgern ob eine konkrete Belegung von \(I\) eine Lösung darstellt oder nicht. Aber wir werden nie wissen ob \(P\) nicht doch vielleicht eine Lösung hat.
Kleiner Exkurs: Tatsächlich können wir das Problem für eine kleine Anzahl an Paaren wirklich entscheiden (für ein oder zwei Paare ist das Problem nach Ehrenfeucht und Rozenberg (1981) entscheidbar)! Für die Anzahl zwischen zwei und drei Paaren ist es noch nicht ganz geklärt, während die Anzahl von sieben paaren bereits ausreicht um von Unentscheidbarkeit zu sprechen (Matiyasevich, 1996).
Noch ein Exkurs: Eine weitere Möglichkeit zu zeigen, dass das Post’sche Korrespondenzproblem nicht entscheidbar ist die Reduktion einer nicht entscheidbaren Menge auf dieses. Aber zum Thema Reduktion kommen wir noch in Teil B der theoretischen Informatik.
Antwort zum Lernziel: Um zu zeigen, dass eine Menge semi-entscheidbar/rekursiv-aufzählbar ist, muss die „halbe“ charakteristische Funktion berechenbar sein. Wir müssen also mit Gewissheit sagen können, ob ein Element zur Menge gehört. Das Gegenteil ist uns hier aber vergönnt und wir nehmen es in Kauf, dass unsere Testmaschine für eine Eingabe im ungünstigsten Fall ewig rechnet.
Dazu gibt muss man ebenfalls man das Flussdiagramm einer verallgemeinerten Maschine angeben, aus der ersichtlich ist, dass sie eine Eingabe in jedem Fall positiv bewertet wenn es denn eine Lösung zum gestellten Problem ist und so lange weiterrechnet bis eine Lösung gefunden ist. Im schlimmsten Fall eben ewig.
Lernziel 6
Erläuterung des Zusammenhangs zwischen rekursiven und rekursiv-aufzählbaren Mengen
Eine spannende, aber offensichtliche Beziehung zwischen entscheidbaren und semi-entscheidbaren Mengen ist: eine Menge ist entscheidbar wenn die Menge selbst und ihr Komplement semi-entscheidbar sind. Formal ausgedrückt:
Eine Menge \(A \subseteq \mathbb{N}^k\) ist rekursiv, gdw. \(A\) und \(\mathbb{N}^k\setminus A\) r.a. sind.
Nehmen wir also an, wir haben eine semi-entscheidbare Menge \(A\subseteq\mathbb{N}\). Wie wir wissen, ist sie semi-entscheidbar, d.h. wir können entscheiden ob ein Element zu dieser Menge gehört. Aber nicht das Gegenteil.
Und was wäre dann die Menge \(\mathbb{N}\setminus{A}\)? In dieser Menge wären genau die Elemente, die zwar aus \(\mathbb{N}\) sind, sich aber nicht in \(A\) befinden.
Im Endeffekt haben wir so quasi zwei „halbe“ charakteristische Funktionen, die jeweils einen Teil entscheiden, welchen die andere charakteristische Funktion nicht entschieden hat. Beide zusammen bilden dann eine „volle“ charakteristische Funktion für \(A\).
Beispiel: \(A\subseteq{B}\)
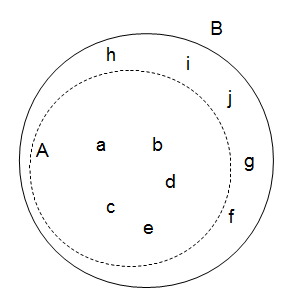
Wir können also die Menge \(A=\{a,b,c,d,e\}\) semi-entscheiden. Ob ein Element nicht in der Menge \(A\) ist hingegen nicht.
Und was wäre wenn wir das Komplement \({B\setminus{A}}\) entscheiden könnten? Also nur die Elemente \({B\setminus{A}}=\{f,g,h,i,j\}\)? Dann könnten wir für alle Elemente aus \(A\) sagen, ob sie zu Menge \(A\) gehören und für den Rest bestimmen ob sie zu \({B\setminus{A}}\) gehören. Damit würde für jedes Element eine positive und negative Entscheidung gefällt werden könne.
Und wenn das der Fall ist, ist \(A\) was? Genau! Komplett entscheidbar/rekursiv.
Die charakteristische Funktion \(cf_A\) für \(A\) wäre also:
\(\chi_A(x)=\begin{cases} 1, & \mbox{ falls } x \in A \\ 0, & \mbox{ wenn } x\in B\end{cases}\)
Fertig. Damit ist die Menge \(A\) (und natürlich auch \(B\)) rekursiv/entscheidbar.
Antwort zum Lernziel: Ist es uns möglich die Teilmenge einer anderen Menge \(A\subseteq{B}\) positiv (aber nicht negativ) zu entscheiden, so ist diese semi-entscheidbar. Können wir für den Rest, d.h. die Menge ohne die bereits positiv entschiedene Menge \(B\setminus A\) ebenfalls entscheiden, so ist die gesamte Menge \(A\) damit rekursiv/entscheidbar.
Weiter geht es mit den nächsten Lernzielen im Beitrag zum Bild- und Projektionssatz.
Bei Fehlern gilt wie immer: ASAP in die Kommentare damit.