Update: mir sind einige Schnitzer beim Halteproblem aufgefallen, die ich mittlerweile ausgeräumt haben sollte. Hoffe ich. Auch habe ich den Beitrag um den Beweis zum Bild- und Projektionssatz erweitert (der nun in einem eigenen Beitrag steht), was ihn leider um ein paar Seiten verlängert hat.
Es gibt insg. drei vier Beiträge zur KE6.
Es sind nur noch ein paar Lernziele übrig, halten wir uns also ran.
Lernziel 7a
Halte- und Selbstanwendbarkeitsproblem
Die beiden Probleme sind definiert als die Mengen:
\(K_\varphi := \{i \in \mathbb{N} \mid \varphi_i(i) \mbox{ existiert}\}\)
\({K_{\varphi}}^0 := \{(i,x) \in \mathbb{N}^2 \mid \varphi_i(x) \mbox{ existiert}\}\)
Wichtig: Komplemente \(\mathbb{N}\setminus{}K_\varphi\) und \(\mathbb{N}^2\setminus{K_{\varphi}}^0\) sind nicht r.a.
In den meisten Fällen wird zunächst gezeigt, dass das spezielle Halteproblem nicht entscheidbar ist. Anschließend wird das spezielle Problem auf das allgemeine zurückgeführt („Wenn schon nicht entscheidbar ist, ob eine Maschine auf ihrem eigenen Wort hält, wie kann man dann entscheiden ob es das für alle Eingabeworte tut?“).
Fangen wir daher auch zunächst mit dem speziellen Halteproblem an.
Spezielles Halteproblem
Das ist die Fragestellung ob Die Maschine mit der Nr. \(i\) bei der Eingabe von \(i\) (die Maschine können wir ja als Eingabewort codieren, wie wir ja durch die Standardnummerierung und das utm-Theorem wissen) hält oder nicht.
Diese Problem wird auch das Selbstanwendbarkeitsproblem genannt. Im Skript steht dazu:
„Das Selbstanwendbarkeitsproblem für \(\varphi\) ist rekursiv unlösbar“.
Es bedeutet nichts anderes, als dass die Menge \(K_\varphi\) zwar r.a. ist, aber nicht rekursiv/entscheidbar. Wir können nämlich nicht entscheiden ob eine Maschine existiert, die bei der Eingabe ihrer eigenen Gödelnummer hält oder nicht. Warum?
Es gibt hier, nehmen wir es genau, zwei Möglichkeiten. Beide funktionieren durch Widerspruch, indem gezeigt wird, dass es so eine Maschine nicht geben kann, die dieses Problem entscheidet. Ihr könnt euch also entscheiden welche Art von Darstellung euch eher zusagt.
Da ich einen anschaulichen Beweis für das allgemeine Problem brauchte, habe ich mir die graphische Variante dafür aufgespart und vertröste euch auf hübsche Bildchen im nächsten Abschnitt.
Zunächst ein sehr schöner (wie ich finde) Widerspruchsbeweis für das spezielle Halteproblem.
Klassischer Widerspruchsbeweis für das spezielle Halteproblem
Es gibt also noch eine Methode, die weniger graphischen Umgang mit Open Office Produkten erfordert, wir damit aber dennoch eine schöne, logische Kette von Schlüssen ziehen können und dabei zu einem Widerspruch gelangen.
Dazu bemühe ich das Barbier-Paradoxon wie Socher in seinem Buch (siehe oben rechts) und zitiere ihn:
Dieser klassische Widerspruchsbeweis hat große Ähnlichkeit mit dem Barbier-Problem, der sog. Russelschen Antinomie:
Man kann einen Barbier als einen definieren, der all jene und nur jene rasiert, die sich nicht selbst rasieren.
Die Frage ist: Rasiert der Barbier sich selbst?
Wenn man versucht die Frage zu beantworten, landet man stets in einem Widerspruch. Wie bei der folgenden Überlegung für das spezielle Halteproblem:
- Nehmen wir an die Männer, die sich selbst rasieren sind unsere Turing-Maschinen \(M_i\), die sich selbst, also \(i\), akzeptieren. Sie halten bei der Eingabe ihrer eigenen Gödelnummer. Formal:
\(M_i(i)\) existiert.
Annahme: es gibt eine Maschine \(H\), die \(1\) ausgibt wenn die Maschine \(M_i\) bei ihrer Gödelnummer hält und ansonsten in eine Endlosschleife gerät. Formal:
\(H(i)=\begin{cases} 1, & \mbox{ falls } M_i(i)\mbox{ existiert} \\ \perp, & \mbox{ sonst}\end{cases}\)
- Nun konstruieren wir die Maschine \(B\) (den Barbier), diese sagt uns ob die Maschine \(M_i\) bei der Eingabe ihrer Gödelnummer \(i\) hält oder nicht indem er die Maschine \(H\) mit einer Gödelnummer startet. Gibt uns \(H\) eine \(1\) zurück, so gerät \(B\) in eine Endlosschleife. Gerät \(H\) in eine Endlosschleife, akzeptiert \(B\) die Ausgabe. Formal:
\(B(i)=\begin{cases} 1, & \mbox{ falls } H(i)=\perp \\ \perp, & \mbox{ falls }H(i)=1\end{cases}\)
In anderen Worten:
\(B\) akzeptiert \(M\) genau dann wenn \(M\) sich nicht selbst akzeptiert
Da wir im Endeffekt ja \(M=B\) haben wenn wir \(B\) auf sich selbst ausführen, so ist das Dilemma, in welches wir laufen genau das Barbier-Paradoxon von Russel:
\(B\) akzeptiert \(B\) genau dann wenn \(B\) sich nicht selbst akzeptiert
Fall 1: \(B\) hält, wir starten \(B\) mit seiner eigenen Nr. \(i\)
\(B(i)=1\Rightarrow H(i)=\perp\Rightarrow M_i(i)=\perp\Rightarrow B(i)=\perp\). Widerspruch!
Fall 2: \(B\) hält nicht, wir starten \(B\) also mit seiner eigenen Nr. \(i\)
\(B(i)=\perp\Rightarrow H(i)=\perp\Rightarrow M_i(i)=1\Rightarrow B(i)=1\). Widerspruch!
Denn in beiden Fällen ist ja \(B=M\)
Damit kann es keine Maschine geben, die das spezielle Halteproblem entscheidet.
Obwohl wir den Regeln der Logik gefolgt sind, stießen wir auf einen Widerspruch. Das bedeutet, dass unsere Grundannahme, so eine Maschine \(B\) könne existieren, falsch war.
Kommen wir nun zum allgemeinen Halteproblem.
Allgemeines Halteproblem
Zum speziellen Halteproblem, also der Frage ob eine Maschine \(M_i\) angewendet auf sich selbst hält oder nicht gibt es noch die allgemeine Version mit folgender, formalen Definition (Wiederholung von oben):
\({K_{\varphi}}^0 := \{(i,x) \in \mathbb{N}^2 \mid \varphi_i(x) \mbox{ existiert}\}\)
Anders ausgedrückt:
Hält die Maschine \(M_i\) bei der Eingabe von \(x\)?
Zuerst nochmal die Wiederholung: wann ist eine Menge \(A\subseteq{B}\) entscheidbar? Genau dann wenn neben \(A\) auch das Komplement \(B\setminus{A}\) semi-entscheidbar ist.
Die Menge \({K_{\varphi}}^0\) ist selbst r.a.. Warum? Wenn eine Maschine \(i\) bei der Eingabe \(x\) hält, dann hält sie. Wir haben in jedem Fall bei einem positiven Entscheid eine Ausgabe und damit einen positiven Entscheid (sofern es den gibt). Ansonsten rechnet die Maschine ewig weiter.
Wir können die Elemente der positiven Menge \((i,x)\) („Hält Maschine \(i\) bei Eingabe von \(x\)„) also „aufzählen“. Wenn sie denn wirklich hält. Die Elemente der anderen Menge, die Menge der Kombinationen von \((i,x)\), wo eine Maschine \(M_i\) bei der Eingabe von \(x\) nicht hält aber eben nicht (im ungünstigsten Fall rechnet die Maschine \(i\) bei der Eingabe von \(x\) nämlich ewig).
Diese positive Menge nennen wir eben
\({K_{\varphi}}^0\)
Die negative Menge ist das Komplement davon, nämlich:
\(\mathbb{N}^2\setminus{K_{\varphi}}^0\)
Während die obere, wie erwähnt, semi-entscheidbar/rekursiv-aufzählbar ist, ist es das Komplement leider nicht. Wäre sie das, so wären alle unsere Probleme gelöst und die Menge \({K_{\varphi}}^0\) wäre entscheidbar/rekursiv.
Formal ausgedrückt müsste für die Semi-Entscheidbarkeit von \(\mathbb{N}^2\setminus{K_{\varphi}}^0\) die „halbe“ charakteristische Funktion berechenbar sein:
\(\chi^{‚}_{{{K_{\varphi}}^0}(i,x)}=\begin{cases} 1, & \mbox{ falls }i\text{ bei der Eingabe von }x\text{ haelt}\\ \perp, & \mbox{sonst}\end{cases}\)
\(\chi^{‚}_{{K_{\varphi}}^0}\) ist, wie wir gemerkt haben berechenbar. Damit ist unsere Menge \({K_{\varphi}}^0\) aber leider nur r.a.
Wäre aber nicht schlimm: Wenn wir zeigen können, dass \(\mathbb{N}\setminus{K_{\varphi}}^0\) auch r.a. ist, so wäre \({K_{\varphi}}^0\) der Definition nach entscheidbar. Warum das nicht geht, zeigen wir jetzt.
\(\chi^{“}_{{{\mathbb{N}^2\setminus K_{\varphi}}}^0(i,x)}=\begin{cases} 1, & \mbox{ falls }i\text{ bei der Eingabe von }x\text{ nicht haelt}\\ \perp, & \mbox{sonst}\end{cases}\)
Da wir nicht wissen, ob die Maschine \(i\) bei der Eingabe von \(x\) niemals hält oder einfach nur noch nicht gehalten hat weil sie noch rechnet, können wir die Funktion \(\chi^{“}_{{{\mathbb{N}^2\setminus K_{\varphi}}}^0(i,x)}\) nicht berechnen. Das leuchtet eig. schon direkt ein.
Aber um das alles noch komplett ad absurdum zu führen tun wir folgendes:
Beweis anhand des speziellen Halteproblems
Wie wir gesehen haben, ist das spezielle Halteproblem nicht lösbar. Daraus folgt auch ganz simpel, dass es keine Maschine \(H(i,x)\) geben kann, die für jedes \(x\) entscheidet ob Maschine \(M_i\) bei der Eingabe von \(x\) hält oder nicht.
Warum? Weil eines der \(x\) auch die Nummer der Maschine \(M_i\) selbst ist, d.h. \(x=i\). Und wir wir haben im letzten Abschnitt gesehen, dass genau das nicht geht.
Einfach, nicht? Und wenn wir die Unlösbarkeit des allgemeinen Halteproblems beweisen wollen, ohne zuerst die Unlösbarkeit des speziellen Halteproblems bewiesen zu haben? Dann machen wir das mit einem klassischen, graphischen Widerspruchsbeweis durch Diagonalisierung.
Graphischer Widerspruchsbeweis mittels Diagonalisierung
Dieser Beweis ist dem Diagonalverfahren von Cantor sehr ähnlich und ist im Grunde auch ein Beweis für das spezielle Halteproblem.
Was haben wir vor? Wir machen hier einfach eine Annahme, dass es eine best. Maschine gibt und zeigen, dass es sie nicht geben kann. Wir führen unsere Annahme also zu einem Widerspruch. Ganz einfach.
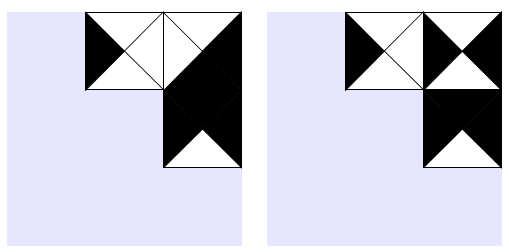
Konstruieren wir zunächst eine Matrix, wo wir auf der \(y\)-Achse alle unsere Maschinen aufsteigend ihrer Gödelnummer \(0,…,n\) auflisten. Auf der \(x\)-Achse stehen alle Eingabeworte \(1^0, …, 1^x\). In den Zellen steht dann drin ob die Maschine für die Eingabe des Wortes hält oder nicht:

Gäbe es eine Maschine, die entscheiden könnte ob eine andere Maschine bei der Eingabe hält, so würde sie uns genau diese Matrix konstruieren.
In dieser Matrix stehen alle Maschinen und alle Worte drin. Nun basteln wir uns eine neue Maschine \(H\), welche zum Eingabewort \(1^i\) das Matrixelement \((i,i)\) berechnet und sich genau entgegengesetzt zur Maschine \(T_i\) verhält (sie hält wenn dort \(T_i\) bei der Eingabe von \(i\) nicht halten würde und läuft in eine Endlosschleife wenn dort \(T_i\) halten würde).
Diese neue Maschine \(H\) ist ja selbst eine Turing-Maschine. Damit müssten wir sie ja in unserer Matrix vorfinden. Tun wir aber nicht, denn egal wo wir nachschauen: unsere neue Maschine hat bei seinen Berechnungen immer mindestens einen unterschiedlichen Ergebniswert als Maschine \(T_i\) beim Wort \(i\) und ist daher tatsächlich neu. Was aber nicht sein kann, denn wir haben in der Matrix nach Definition alle Turingmaschinen bereits drin.
Widerspruch!
Etwas abstrakt, aber durchaus logisch nachvollziehbar. Das ist das schöne an Widerspruchsbeweisen. Falls Ihr das nicht direkt beim Lesen nachvollziehen konntet: schreibt euch das einfach auf’s Papier. Dann kommt der „Aha-Effekt“, versprochen.
Wem das zu abstrakt war, der schaue sich nochmal folgenden Beitrag an. Dort wird die Überabzählbarkeit von \(\mathbb{R}\) mit dem gleichen Verfahren bewiesen.
Zusammenfassend wird die Beweisführung häufig nach folgendem Muster geführt:
- spezielles Halteproblem (auch Diagonalsprache genannt), wo die Maschine auf sich selbst angewendet wird, ist nicht entscheidbar. Gezeigt wird es meist durch Diagonalisierung.
- Komplement dieser Menge ist nicht einmal semi-entscheidbar, da wir dazu diese „Diagonalisierungsmaschine“ bräuchten. Und diese kann es ja nicht geben.
- Daraus folgt, dass das allgemeine Halteproblem auch nicht entscheidbar ist. Denn sonst wäre sein Komplement semi-entscheidbar. Das geht aber nicht, da eine Eingabe das eigene Wort der Maschine ist. Und wie wir bewiesen haben, kann es keine Maschine geben, die entscheidet ob eine Maschine angewendet auf sich selbst hält oder nicht.
Antwort zum Lernziel: das Halteproblem bezeichnet die Fragestellung ob eine Maschine bei der Eingabe eines Eingabewertes hält oder nicht. Es ist nur semi-entscheidbar/rekursiv-aufzählbar.
Bei dem speziellen Halteproblem ist die Fragestellung ob eine Maschine angewendet auf seine eigene Gödelnummer hält oder nicht. Diese Menge ist ebenfalls nur semi-entscheidbar/rekursiv-aufzählbar.
Die Komplemente dieser Fragestellungen sind nicht semi-entscheidbar/rekursiv-aufzählbar (wir können nicht wissen ob die Maschine nie hält oder nur noch rechnet und doch noch halten wird). Wären sie das, so wären auch die Halteprobleme entscheidbar/rekursiv.
Lernziel 8
Erklärung der Reduzierbarkeit und Methode der Reduktion
Reduzierbarkeit, formal definiert heißt:
\(A \leq B : \Longleftrightarrow \exists f \in R^{(1)}. A = f^{-1}[B]\)
\(A\) ist reduzierbar auf \(B\) genau dann wenn die Menge \(A\) eine Urbildmenge von \(B\) unter \(f\) ist.
Schon wieder sowas komisches. Das bekommen wir aber auch noch klein. Zunächst einmal haben wir eine wunderschöne, einstellige, rekursive Funktion \(f\), welches uns zu einem \(x\) aus \(A\) ein Bild liefert, welches selbst in \(B\) liegt. Damit ist \(A\) die Urbildmenge von \(B\).
Etwas formaler ausgedrückt und wortwörtlich aus dem Skript:
\((x \in A \Rightarrow f(x) \in B)\) und \((x \notin A \Rightarrow f(x) \notin B)\).
Liegt ein \(x\) in \(A\), so liegt auch sein Bild (Funktionswert) \(f(x)\) in \(B\). Liegt ein \(x\) nicht in \(A\), so liegt auch sein Bild nicht in \(B\).
Die Abschlusseigenschaften der Reduzierbarkeit sind (wir haben als Annahme 3 Mengen \(A,B,C \subseteq \mathbb{N}\)) sind ähnlich denen aus Abschlusseigenschaften rekursiver Mengen:
1. \(A \leq B\) und \(B \leq C \Rightarrow A \leq C\)
Erläuterung: Ist \(A\) reduzierbar auf \(B\) und \(B\) reduzierbar auf \(C\), so ist auch \(A\) reduzierbar auf \(C\). Simple Transitivität.
2. \(A \leq B\Longleftrightarrow\mathbb{N}\setminus{A}\leq\mathbb{N}\setminus{B}\)
Erläuterung: Die Transitivität gilt auch für Komplemente von \(A\) und \(B\).
3. \(A \leq B\) und \(B\) rekursiv \(\Rightarrow A\) rekursiv
4. \(A \leq B\) und \(B\) rekursiv aufzählbar \(\Rightarrow A\) rekursiv aufzählbar
Erläuterung: Auch übernimmt die reduzierte Menge \(A\) die Eigenschaften der Menge \(B\). Ist Menge \(B\) r.a. oder rekursiv, so ist es auch die Menge \(A\) wenn man sie erfolgreich auf \(B\) reduzieren konnte.
Die Reduktion ist ein wichtiges Hilfsmittel. Nicht nur jetzt, sondern – wie gesagt – auch für die Reduktion in den Komplexitätsklassen \(P\), \(NP\), usw. Dazu aber in den nächsten Beiträgen mehr.
Was können wir derweil damit tun?
Beispiel: Reduktion des spezielle Halteproblem auf das allgemeinen Halteproblems
Ist doch ein nettes Beispiel für eine Reduktion, oder?
Formal suchen wir daher eine totale Funktion \(f:\mathbb{N}\rightarrow\mathbb{N}^2\), die unser spezielles Halteproblem auf das allgemeine reduziert. Es muss gelten:
\(B(i)=H(f(i))\)
Erinnerungshilfe: \(B\) ist unsere Maschine (der Barbier), die unser spezielles Halteproblem entscheiden sollte. Und \(H\) die Maschine, die unser allgemeines Halteproblem entscheiden durfte.
Wir definieren nun \(f\) mit
\(f(i)=(i,i)\)
Damit gilt auch: \(B(i)=H(i,i)\) und wir haben damit das spezielle Halteproblem auf das allgemeine reduziert.
Nicht vergessen: die Reduktion ist transitiv, reflexiv aber nicht antisymmetrisch.
Antwort zum Lernziel: Die Reduktion ist ein mächtiges Werkzeug um Probleme auf ein anderes zurückzuführen. Gibt es einen Algorithmus, der das Problem entscheidet, worauf reduziert wurde, so kann auch das reduzierte Problem entschieden werden.
Aber nicht nur für die Berechenbarkeit hat es Auswirkungen, sondern auch auf die Eigenschaften der reduzierten Mengen und ihre Komplemente. Ist die Menge, auf die reduziert wurde rekursiv oder rekursiv-aufzählbar, so ist die reduzierte Menge ebenfalls rekursiv oder rekursiv-aufzählbar.
War die Reduzierung der Mengen möglich, so ist auch die Reduzierung ihrer Komplemente möglich.
Lernziel 9
Satz von Rice
Kommen wir nun zu einem der wichtigsten Sätze der theoretischen Informatik, den Hr. Gordon Rice im Jahre 1953 aussprach.
Im Skript ist er formal definiert als:
Für jede Menge \(F\subseteq P^{(1)}\) mit \(F\neq\emptyset\) und \(F\neq P^{(1)}\) ist die Menge \(\varphi^{-1}[F]\) nicht rekursiv/entscheidbar.
In der Wikipedia ist der Satz in einer anderen Form zu lesen.
Zunächst: was ist unser Wunsch? Wir würden gerne wissen, ob eine Funktion eine Eigenschaft hat oder nicht. Was wäre so eine Eigenschaft? Zum Beispiel:
- Programm \(P\) berechnet die Identitätsfunktion
- Die Ausgabe des Programms \(P\) ist maximal \(n\) Zeichen lang
- …
Denkt euch einfach was nicht triviales (was nicht trivial genau bedeutet erkläre ich auch gleich) aus.
Es kann durchaus mehrere Programme (und damit auch mehrere Maschinen) geben, die Funktionen berechnen. Sagen wir einfach mal, wir betrachten
\(F:=\{f\in{P^{(1)}}\mid{f(x)=x}\}\).
Da die Identitätsfunktion berechenbar ist, gibt es eine Programm, die sie berechnet. Sagen wie auch: Es ist das kleinste Programm \(P_f\), das sie berechnet.
Nun konstruieren wir ein weiteres Programm \(P_{f_2}\), das zusätzlich zum Programmcode von \(P_f\) noch eine sinnlose Schleife besitzt, die eine ungenutzte Variable bis \(5\) hochzählt. Offensichtlich berechnet auch \(P_{f_2}\) die Identitätsfunktion. Programm \(P_{f_2}\) ist von \(P_f\) aber verschieden und beide haben auch verschiedene Gödelnummern.
Wir reden aber nicht explizit von Programmen, sondern von den Funktionen, die sie berechnen. Obwohl die Programme \(P_{f}\) und \(P_{f_2}\) verschieden sind, berechnen sie ein und die selbe Funktion: \(f_P=f_{P_2}=Id\). Damit erfüllen sie unsere „Eigenschaft“ \(F\) und wir haben schon mindestens zwei Programme, bzw. ihre Gödelnummern in unserer Menge
\(\varphi^{-1}[F]\) bzw.
\(\{i\mid{\varphi_i\in{F}}\}\)
Was \(\varphi\) ist, wisst Ihr noch? Im Beitrag zur Standardnummerierung hatten wir das bereits. Damit hatten wir alle Funktionen aus \(P^{(1)}\), der Menge der einstelligen, berechenbaren, evtl. partiellen Funktionen nummeriert. Die Gödelnummern \(i\) und \(i_2\) von \(P_{f}\) und \(P_{f_2}\) befinden sich daher in dieser Menge \(\varphi^{-1}[F]\). Und auch noch viele weitere Gödelnummern von Programmen, die unsere Identitätsfunktion \(f(x)=x\) berechnen.
Das Problem ist: diese Menge von Gödelnummern, die die Eigenschaft \(F\) besitzt, ist nach dem Satz von Rice nicht entscheidbar!
Das ist die Kernaussage des Satzes. Nach diesen Erläuterungen können wir die Definition von oben Stück für Stück auseinander nehmen:
Sei \(F\) eine nicht leere (\(F\neq\emptyset\)) echte Teilmenge (\(F\neq P^{(1)}\) und gleichzeitig \(F\subseteq P^{(1)}\)) der Turing-berechenbaren, einstelligen Funktionen. Es ist nicht entscheidbar welche Funktionen, die durch das Programm \(i\) gegeben ist, die Eigenschaft \(F\) hat und welche nicht (\(\varphi^{-1}[F]\) ist nicht rekursiv).
Diese beiden Eigenschaften der Menge \(F=\emptyset\) (es ist die leere Menge) oder \(F=P^{(1)}\) (das ist die komplette Menge der berechenbare, einstelligen Funktionen) werden auch triviale Eigenschaften genannt. Es bedeutet, dass es min. ein Programm geben muss, die diese Funktion berechnet und eines, das sie nicht berechnet.
Wann ist der Satz von Rice also anwendbar? Wenn es um die Eigenschaften von Funktionen (und nicht um die konkreten Maschinen selbst) geht und wenn die Menge der Programme, die diese Funktion berechnen nicht leer ist oder die Klasse der betrachteten Funktionen nicht komplett alle berechenbaren, einstelligen Funktionen umfasst.
Exkurs: Maschine/Programm?!
Warum wird manchmal auch von den Eigenschaften von Turingmaschinen und nicht von Funktionen gesprochen? Erinnert Ihr euch noch an die Church’sche These? Die Klasse der intuitiv berechenbaren Funktionen stimmt der der Klasse der Turing-berechenbaren Funktionen überein.
Damit können alle intuitiv berechenbaren Funktionen von Turingmaschinen berechnet werden und so die Eigenschaften von Funktionen auch die Eigenschaften der Turingmaschinen sein.
Da die Programme, die eine Funktion aus \(P^{(1)}\) berechnen im Endeffekt also bloß Turingmaschinen sind, die die Funktion aus \(P^{(1)}\) berechnen, sind die Gödelnummern der Programme auch die Gödelnummern der zugehörigen Bandmaschinen.
Lasst euch also von den Worten Funktion, Programm, Maschine nicht verwirren 😉
Noch nicht so recht greifbar, oder? Macht nichts. Versuchen wir es mit ein paar Negativbeispielen:
Negativbeispiele
\(F_1=\{i\mid{M_i}\text{ haelt bei der Eingabe von }x\text{ in }5\text{ Schritten }\}\)
\(F_2=\{i\mid{M_i}\text{ hat 20 Zustaende}\}\)
Diese Mengen \(F_1\) und \(F_2\) sind entscheidbar.
In beiden Fällen ist der Satz von Rice nicht anwendbar, da sich die Aussage nicht auf die Funktionen, d.h. die Maschinenmenge, die sie berechnet, sondern auf die konkreten Eigenschaften einer Maschinen bezieht.
Und nun ein paar Positivbeispiele:
Positivbeispiele
\(F_3=\{i\mid{M_i}\text{ haelt nur bei endlich vielen Eingaben}\}\)
\(F_4=\{i\mid{M_i}\text{ berechnet }0\text{ bei Eingabe von }1\}\)
Hier lässt sich der Satz von Rice anwenden.
- Wir prüfen Voraussetzungen \(F\subseteq{P^{(1)}}\) und \(F\neq{P^{(1)}}\):
In \(P^{(1)}\) liegt z.B. \(f(x)=x^2\), damit gilt \(F_3\subseteq{P^{(1)}}\) und \(F_3\neq{P^{(1)}}\).
- Wir prüfen Voraussetzung \(F_3\neq\emptyset\):
Zudem gilt auch \(F_3\neq\emptyset\), denn es gibt min. eine Maschine, die nur bei endlich vielen Eingaben hält, z.B. \(M(x)=1\text{ falls } x<5,\text{ sonst }\perp\). Damit hält Maschine \(M\) nur für \(x<5\).
Die Menge \(F_3\) ist nach Rice somit nicht entscheidbar.
Für \(F_4\) gilt das ebenfalls. Die Prüfung der Voraussetzungen geht analog zu \(F_3\). Auch diese Menge ist nach Rice nicht entscheidbar.
Fazit: Wann können wir den Satz von Rice anwenden? Wenn mindestens eine Maschine (ein Programm) gibt, die die Funktionen aus der zu untersuchenden Menge \(F\) berechnet und es Maschinen (Programme) gibt, die die Funktionen aus \(F\) nicht berechnen.
Genau das ist es, was uns vor Augen führt, dass das Halteproblem unentscheidbar ist. Es ist nämlich eine nicht triviale Eigenschaft und wir können sie nach dem Satz von Rice nicht entscheiden. Damit ist die Menge \(K_{\varphi}^0\) nicht rekursiv/entscheidbar.
Der Satz hat auch weitreichende Folgen im realen Leben. Denn er bedeutet z.B., dass es kein Verifikationswerkzeug in der Softwareentwicklung geben kann, welches alle Programme algorithmisch auf Korrektheit bzgl. ihrer Spezifikation prüft. Es kann welche geben, die bestimmte, ggf. auch alle praktisch relevanten Programme testen können, aber alle? Das geht nach dem Satz von Rice eben nicht.
Aber Achtung: für Teilmengen von \(F\) ist es evtl. möglich, diese zu entscheiden. Daher auch das Beispiel mit der Verifikationssoftware: wir können nicht für jedes Programm entscheiden ob es der Spezifikation entspricht, aber evtl. durchaus für eine Teilmenge davon. Vielleicht ist das gerade die für uns relevante (praxisrelevante) Teilmenge.
Auch wenn die soeben genannte Eigenschaft „Das Programm arbeitet bzgl. seiner Spezifikation korrekt“ bereits praxistauglich ist, so gibt es eine weitere nicht triviale Eigenschaft von Programmen, mit der wir es tagtäglich zu tun haben: die Frage ob ein Programm eine schädliche Funktion hat oder nicht!
Genau diese Fragestellung hat auch weitreichende Folgen für die Antiviren-Hersteller. Aus dem Satz von Rice lässt sich schließen, dass es kein Antiviren-Programm geben kann, dass für alle Programme entscheiden kann ob sie schädlich sind oder nicht.
Antwort zum Lernziel: Der Satz von Rice hat weitreichende Auswirkungen auf die Praxis. Er besagt, dass nicht triviale Aussagen über eine von einer Turingmaschine berechnete Funktion (ein Programm) nicht entscheidbar sind.
Diese nicht trivialen Aussagen sind Aussagen der Form \(F\neq{P^{(1)}}\) und \(F\neq\emptyset\). Es muss also min. eine Maschine geben, die die Eigenschaft besitzt und min. eine, die sie nicht besitzt.
Um den Satz anwenden zu können, muss man die zu überprüfende Eigenschaft auf diese Voraussetzungen zunächst testen. Werden die Voraussetzungen bzg. der Nicht-Trivialität erfüllt und bezieht sich die Aussage auf eine Funktion und nicht auf die konkrete Maschine, so kann der Satz angewandt werden.
Vielleicht nochmal in anderen Worten (diese habe ich aus irgendeiner Vorlesung, ich weiß aber nicht mehr welcher):
Geben ist eine nicht-triviale Eigenschaft \(F\). Die Menge der Programme, die diese Eigenschaft erfüllen ist unentscheidbar.
Aber Achtung: für eine Teilmenge könnte die Eigenschaft durchaus entscheiden werden, jedoch eben nicht für alle!
Lernziel 7b
Äquivalenz- und Korrektheitsproblem
Kommen wir nun zum Äquivalenz- und Korrektheitsproblem. Das sind beides nicht triviale Eigenschaften von Programmen und damit nicht für alle entscheidbar.
Aber zunächst wieder die Definition, dann die Erklärung:
Es sei \(d:\subseteq \mathbb{N} \rightarrow \mathbb{N}\) definiert durch \(d(i) = div\) für alle \(i \in \mathbb{N}\)
1. Für jedes \(f \in P^{(1)}\setminus \{d\}\) sind die Mengen \(M_f := \{i\mid\varphi_i = f\}\) und \(\mathbb{N}\setminus M_f = \{i\mid\varphi_i \neq f\}\) nicht rekursiv aufzählbar.
2. Die Mengen Äq \(:= \{(i,j)\mid\varphi_i = \varphi_j\}\) und \(\mathbb{N}^2\setminus\) Äq = \(\{(i,j)\mid\varphi_i \neq \varphi_j\}\) nicht rekursiv aufzählbar.
Als erstes haben wir eine Funktion \(d\), welche für jedes Argument divergent ist.
Punkt 1, Korrektheitsproblem: für jede Funktion \(f\) aus den einstelligen, evtl. partiellen, berechenbaren Funktionen \(P^{(1)}\) ohne die überall undefinierten Funktionen \(d\), sind die Mengen \(M_f\), welche aus den Gödelnummern der Programme/Maschinen bestehen, welche die Funktion \(f\) berechnen und der Menge \(\mathbb{N}\setminus M_f = \{i\mid\varphi_i \neq f\}\), der Menge aus den Gödelnummern, welche die Funktion nicht berechnen nicht rekursiv aufzählbar.
Diese Menge ist also nicht einmal semi-entscheidbar, d.h. wir haben keinen Algorithmus, der uns zu einem gegebenen \(f\) für alle \(\varphi_i\) entscheidet ob \(\varphi_i\) die Funktion \(f\) korrekt berechnet. Auch das Komplement davon, die Menge der Programme die die Funktion \(f\) nicht berechnen ist nicht semi-entscheidbar.
In der Praxis würde man das Beispiel aus dem Skript bemühen, wo eine Korrektor ein Testprogramm entwerfen möchte, welches entscheidet ob ein gegebenes Programm die Funktion \(f\) berechnet.
Punkt 2, Äquivalenzproblem: Die Menge Äq, welche aus Tupel \((i,j)\) der Gödelnummern von Maschinen besteht, welche die gleiche Funktion berechnen (\(\varphi_i=\varphi_j\), sie sind äquivalent zueinander) und der Menge \(\mathbb{N}^2\setminus\)Äq, die aus Tupeln besteht, welche nicht die gleiche Funktion berechnen sind nicht semi-entscheidbar/rekursiv aufzählbar.
Das Äquivalenzproblem kann auf das Halteproblem zurückgeführt werden. Eine Maschine, die uns eine \(1\) ausgibt, wenn zwei Maschinen die gleiche Funktion berechnen, kann uns auch das Halteproblem lösen. Da die Korrektheit und die Äquivalenz eine nichttriviale Eigenschaft eines (oder mehrerer) Maschinen sind, gilt mit dem Satz von Rice (siehe oben), dass man beides nicht entscheiden kann (nur für reguläre Sprachen geht das, aber das wird später noch durchgekaut).
Antwort zum Lernziel: Das Korrektheitsproblem besagt, dass die Menge der Programme, die eine Funktion berechnen nicht einmal semi-entscheidbar ist. Diese Feststellung gilt ebenfalls für die Menge der Programme, welche die gleiche Funktion berechnen (Äquivalenzproblem).
Man kann das Korrektheitsproblem auf das Äquivalenzproblem durch \(f(i)=(i,j)\) reduzieren.
Lernziel 10
Gödel’scher Unvollständigkeitssatz
Der Unvollständigkeitssatz von Gödel besteht aus zwei Teilen (zitiert nach Wikipedia).
Der Erste Unvollständigkeitssatz besagt, dass es in hinreichend starken widerspruchsfreien Systemen immer unbeweisbare Aussagen gibt.
Der Zweite Unvollständigkeitssatz besagt, dass hinreichend starke widerspruchsfreie Systeme ihre eigene Widerspruchsfreiheit nicht beweisen können
Der Teil ist im Skript wirklich gut beschrieben. Es ist einer der wichtigsten Sätze der Logik (Formulierung geklaut aus Wikipedia). Daher würde diesem Lernziel gerne einen eigenen Beitrag widmen.
Also: bitte dort lesen und dann hierher zurück um den Beitrag mit der Antwort zum letzten Lernziel von Kurseinheit 6 abzuschließen 😉
Antwort zum Lernziel: Mit dem Unvollständigkeitssatz kann man sagen, dass nicht jeder mathematische Satz aus den Axiomen formal abgeleitet oder widerlegt werden kann. Kurz gesagt:
Jedes hinreichend mächtige formale System ist entweder widersprüchlich oder unvollständig.
Durch ein Paradoxon können selbst in so einfachen Systemen, wie z.B. Peano, Widersprüche konstruiert und bewiesen werden, so dass es unvollständig bzw. widersprüchlich ist.
Wir haben im Endeffekt also entweder ein widersprüchliches oder ein unvollständiges System (mit letzterem können wir jedoch besser leben).
Und damit haben wie die Kurseinheit 6 auch schon durch. Wer Fehler findet, sofort melden bevor sie sich in den Köpfen einnisten 😉