Update: Schnitzer im Projektionssatz aufgefallen. Fixed.
Als ich die letzten Beiträge zu Kurseinheit 5 von TIA durchgegangen bin, ist mir aufgefallen, dass einige Beweise doch noch nicht so nachvollziehbar sind, wie ich das gerne hätte.
Nach dem Editieren kam ich auf eine Seitenzahl von über 20. Schon wieder. Da blieb mir also nichts anderes übrig, als den Beitrag zu KE6 erneut zu trennen. Schwierigkeiten machten mir aber die Kommentare zu den Lernzielen als alles noch ein einzelner Beitrag war. Diese zu verschieben war ohne manuellen Eingriff in die Datenbank nicht möglich.
Solltet Ihr daher auf Kommentare treffen, die nicht unbedingt zu dem Beitrag hier passen: meine Schuld. Sie gehören dann zu einem der drei anderen.
Dieser Artikel ist brandneu und die anderen Beiträge zu KE6 sind teilweise massiv überarbeitet worden. Eine erneute Lektüre könnte sich also lohnen wenn Ihr bei KE6 der theoretischen Informatik A noch strauchelt und den Sachverhalt gerne mal in anderen Worten gelesen hättet.
Lange Rede, kurzer Sinn: Das sind also die Beiträge zu Kurseinheit 6.
- TIA: Rekursive und rekursiv-aufzählbare Mengen (Lernziele KE6, 1/4)
- TIA: Bild- und Projektionssatz (Lernziele KE6 2/4)
- TIA: Halte- Äquivalenz- und Korrektheitsproblem, Reduzierbarkeit, Satz von Rice (Lernziele KE6, 3/4)
- TIA: Gödel’scher Unvollständigkeitssatz (Lernziele KE6, 4/4)
Dieser dreht sich komplett um den Bild- und Projektionssatz. Ursprünglich war er nicht einmal eine halbe Seite lang. Als ich den Beweis dann Schritt für Schritt nachvollzog, wuchs er auf die aktuelle Größe heran. Tja, und da ist er nun.
Lernziel 5
Charakterisierung der r.a. Mengen durch Bild- und Projektionssatz
Die Charakterisierung ist wie folgt definiert:
1. \(A \subseteq \mathbb{N}\) ist r.a. gdw. \( A = \emptyset\) oder \(A = Bild(g)\) für ein \(g \in R^{(1)}\)
2. \(A \subseteq \mathbb{N}^k\) ist r.a. gdw. es eine rekursive Menge \(B \subseteq \mathbb{N}^{k+1}\) gibt mit \(A = \{x \in \mathbb{N}^k \mid (\exists t)(x,t) \in B\}\)
Nr. 1 bedeutet, dass eine Menge \(A\) dann rekursiv ist, wenn sie von einer totalen, rekursiven Funktion \(g\) aufgezählt werden kann, d.h. dass \(A\) Bild dieser Funktion ist.
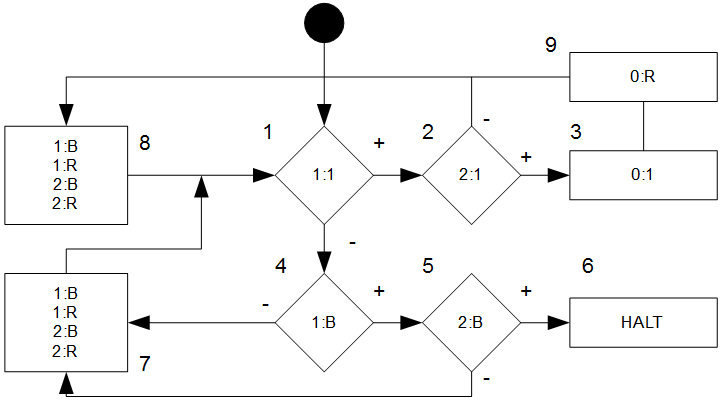
Nr. 2 ist der Projektionssatz: eine Menge ist r.a. wenn sie die Projektion einer rekursiven Menge ist. Das Bild im Skript ist relativ eindeutig wenn man weiß, nach was man schauen muss. Ich nehme hierzu ein konkretes Beispiel mit \(k=1\) und der Menge \(B = \{(1,4),(1,2),(3,3),(3,2),(3,1),(5,1),(6,1)\}\), welche aus \(7\) Tupeln besteht.
Wir haben also zwei Achsen, die wir wie in der Definition \(t\) und \(x\) nennen. So sieht es dann aus:

Das Bild ist angelehnt an das aus dem Skript, nur mit einer Sonne, die ich gleich erkläre. Im Skript steht
„Die Projektion ist der eindimensionale Schatten bei der Beleuchtung von oben“.
Wir machen aus unserem \(2\)-Tupel nun ein \(1\)-Tupel: Uns interessieren nur die \(x\)-Werte aus den Tupeln, und so kommen wir auf die 2. x-Achse im Bild für unser \(A = \{(1),(3),(5),(6)\}\) . Das ist unsere vorderste Front.
Der Projektionssatz sagt also aus:
War unsere Menge \(B\) rekursiv (entscheidbar), so ist unsere Projektion \(A\) rekursiv aufzählbar (r.a.). Die Umkehrrichtung gilt auch: Ist unsere Projektion r.a., so ist die Menge \(B\) entscheidbar.
Aber beweisen wie diese Aussagen zunächst:
1. Teilbeweis zu Nr. 1: \(A\text{ ist r.a.}\Rightarrow{A=\emptyset}\) oder \(A=Bild(g)\) mit \(g\in R^{(1)}\).
Das ist umgangssprachlich am besten so auszudrücken: eine leere Menge \(A=\emptyset\) ist der Definition nach immer rekursiv/entscheidbar. Also Auch immer rekursiv aufzählbar/semi-entscheidbar. Hier gibt es für uns nichts weiter zu beweisen.
Ansonsten gilt: wenn die Menge durch eine totale Funktion aufgezählt werden kann, so ist diese Menge rekursiv-aufzählbar/semi-entscheidbar. Das ist leicht einzusehen: Semi-Entscheidbarkeit einer Menge \(A\) bedeutet ja, dass für für jedes Element aus \(A\) immer einen positiven (oder negativen, aber nicht beides gleichzeitig) Bescheid bekommen und somit auch \(A\) tatsächlich die Bildmenge der Funktion ist, die sie entscheidet: nämlich \(g\) ist.
Haben wir z.B. die Gesamtmenge der Instanzen für das Post’sche Korrespondenzproblem und wollen wir daraus die Menge der lösbaren Instanzen konstruieren, so können wir für jedes Element der Gesamtmenge die Funktion \(g\) laufen lassen, die es in jedem Fall positiv entscheidet wenn eine Lösung dafür gefunden wurde (dass wir das können, haben wir im letzten Beitrag schon gezeigt) und somit jedes Element aus der Menge \(A\), der Menge der gelösten Probleminstanzen, aufzählen.
Genau diese Definition begründet den Namen Art von Mengen: sie werden von \(g\) aufgezählt und sind damit rekursiv aufzählbar.
Das war der erste Teil. Kommen wir nun zum Umkehrschluss.
2. Teilbeweis zu Nr. 1: \(A\text{ ist r.a.}\Leftarrow{A=\emptyset}\) oder \(A=Bild(g)\) mit \(g\in R^{(1)}\).
Fall 1: \(A=\emptyset\): Wir nehmen an, dass die \(A\) leer ist. Nun suchen wir eine Funktion \(d\), die für alle Eingabewerte \(n\) kein Ergebnis liefert und setzen \(A\) als Definitionsmenge dieser Funktion \(d\): \(A=Def(d)\). Damit haben wir den ersten teil gezeigt.
Fall 2: Nun nehmen wir eine totale Funktion \(g\) und setzen \(A\) als Bildmenge von \(g\): \(A=Bild(g)\). Jetzt kommt unser \(f\) ins Spiel:
\(f(y)=\mu{x}[g(x)=y]\)
Was macht \(f\)? Es gibt uns für einen Eingabewert \(y\) das kleinste \(x\), wo gilt, dass der Funktionswert von \(g\) bei der Eingabe von \(x\) genau \(y\) ist.
Man mache sich hier klar, dass egal, was \(g\) als Eingabewert bekommt, wir immer \(div\) zurückbekommen (denn die leere Menge \(A\) ist die Bildmenge von \(g\)).
\(f\) kann im Gegenzug alle Werte aus \(\mathbb{N}\) bekommen und auf alle abbilden. Diese Funktion ist offensichtlich berechenbar.
Das bedeutet: für ein \(y\in{Def(f)}\) gibt es auch ein \(x\) mit \(g(x)=y\). Da \(y\in{Bild(g)}\) ist, gilt: \(Def(f)=Bild(g)\) und \(Bild(g)\) ist somit rekursiv aufzählbar.
Und das war der zweite Teil.
1. Teilbeweis zu Nr. 2: \(A\text{ ist r.a.}\Rightarrow{B}\text{ rekursiv}\)
Zeigen wir zunächst den umgekehrten Weg von Punkt 2 mit: \(A\text{ ist r.a.}\Rightarrow{B}\text{ rekursiv}\). Dafür gehen wir davon aus, dass eine Menge \(A\subseteq\mathbb{N}^k\) rekursiv aufzählbar ist:
- Dann gibt es eine Gödelnummer \(i\) für ein \(x\in{A}\) mit \(\varphi_i(\pi^{(k)}(x))\) existiert.
Es gibt also eine Maschine mit der Nr. \(i\), die uns zum Element \(x\) eine Ausgabe beschert. Die Cantorsche Tupelfunktion \(\pi\) ist hier nur dazu da um eine evtl. Mehrstelligkeit \(k\) der Eingabe für die Maschine auf eine Stelle herunterzurechnen.
- Gibt es die Maschine mit der Nr. \(i\), so gibt es auch selbstverständlich die dazu gehörige Schrittzahlfunktion \(SZ\), die im \(\Phi\)-Theorem benutzt wird: \(\Phi_i(\pi^{(k)}(x))\)
Kennen wir alles schon: das ist die Anzahl der Schritte, die \(\varphi_i\) bei der Eingabe von \(x\) braucht um zum Ende zu gelangen. Da die Menge \(A\) rekursiv aufzählbar ist, existiert für jedes \(x\in{A}\) diese Rechenzeitfunktion \(\Phi_i(x)\).
- Und damit gilt: \((\exists{t})\Phi_i(\pi^{(k)}(x))\leq{t}\)
Es gibt also ein kleinstes \(t\), d.h. die minimale Anzahl der Schritte, die die Maschine \(\varphi_i\) bei der Eingabe von \(x\) rechnet um bis zum Ergebnis zu gelangen. Es gibt aber auch noch mehr \(t’s\). Eben die, die kleiner sind als die maximale Schrittzahl, die die Maschine bei der Eingabe von \(x\) rechnet um bis zur HALT-Marke zu gelangen.
- Nun definieren wir die Menge \(B=\{(x,t)\mid\Phi_i(\pi^{(k)}(x))\leq{t}\}\)
Die Paare sind also die Eingabe \(x\) für die Maschine \(\varphi_i\) und \(t\) die Anzahl der Schritte, die die Maschine bis zum Ergebnis rechnen könnte. Sagen wir z.B. die Maschine rechnet bei der Eingabe von \(x\) genau \(5\) Schritte bis sie an der \(HALT\)-Marke ankommt, so kann \(t\leq{5}\) sein. In der Menge \(B\) würde daher \((x,1)(x,2)(x,3),(x,4),(x,5)\) liegen.
- Nach dem \(\Phi\)-Theorem ist diese Menge \(B\) also entscheidbar.
Das sollte klar sein: das Paar \((x,t)\), also die Eingabe \(x\) und die Rechenzeit \(t\) ist entscheidbar, da wir für jedes \(x\) (wenn es in der Menge \(A\) ist) immer einen Ausgabewert haben, ist auch die maximale Schrittzahl immer gegeben. Wir können entscheiden ob die Maschine bei der Eingabe von \(x\) nach \(t\) Schritten hält oder nicht.
Anders ausgedrückt: Wir können fragen: „Hey, gilt \((x,5)?\) und \(\Phi\) prüft ab ob bei der Eingabe von \(x\) die Maschine innerhalb von \(5\) Schritten zum Ergebnis kommt und kann dann sagen „Ja, das geht!“ oder „Nein, ging nicht!“. Diese Menge ist also Entscheidbar.
Der eine Weg von Punkt 2 ist damit gezeigt.
2. Teilbeweis zu Nr. 2: \({A}\text{ ist r.a.}\Leftarrow{B}\text{ rekursiv}\)
Und nun die andere Richtung: \({A}\text{ ist r.a.}\Leftarrow{B}\text{ rekursiv}\). Sei \(B\subseteq\mathbb{N}^{k+1}\) also rekursiv/entscheidbar.
- Setzen wir die Menge \(A=\{x\in\mathbb{N}^k\mid{}(\exists{t} (x,t)\in{B}\}\)
\(B\) ist, wie wir wissen ja entscheidbar. Zu einer Eingabe erhalten wir (wenn sie zu einer r.a. Menge gehört) auch eine maximale Rechenzeit und können so prüfen ob sie \(t\) entspricht oder größer/kleiner ist. Hier ist \(A\) also die Menge der Eingaben, d.h. die ersten Elemente aus den Tupeln von \(B\), die aus Eingabe \(x\) und zugehörigem Wert für eine angenommene Rechenzeit \(t\) bestehen.
- Nun definieren wir unsere „Projektionsfunktion“ durch
\(f(x):=\mu{t}[cf_B(x,t)=1]\)
Was tut \(f\)? Zunächst fragen wir uns, was tut \(cf_B\)? Das ist die (volle) charakteristische Funktion für die Menge \(B\). Sie gibt uns eine \(1\) zurück wenn die Maschine bei der Eingabe von \(x\) nach maximal \(t\) Schritten hält.
Und \(\mu{t}\)? Sie gibt uns das kleinste \(t\) zurück, d.h. die minimalste Anzahl an Schritten, die benötigt werden um bei der Eingabe von \(x\) von der Maschine eine Ausgabe zu erhalten, denn in unserer menge \(B\) liegen ja durchaus mehrere Kombinationen von \((x,t)\) mit den unterschiedlichsten \(t’s\).
Mit \(f(x)\) bekommen wir das also für die Eingabe \(x\) kleinste \(t\).
Der Definitionsbereich von \(f\) sind somit alle Elemente aus \(A\) und \(A\) damit rekursiv aufzählbar.
Done.
Exkurs: den Unterlagen der Uni Düsseldorf kann man den Projektionssatz auch mit einer anderen Menge \(B\) beweisen, z.B. mit \((x,z)\) (wobei \(x\) die Eingabe und \(z=\pi(y,t)\) das durch die Tupelfunktion \(\pi\) auf ein Element \(z\) zurückgeführte Paar aus Ausgabe \(y\) und Schrittzahl \(t\) ist) wenn \(T_i(x,t)\) (auch Turingprädikat genannt) erfüllt ist.
Das Turingprädikat ist genau dann erfüllt wenn Maschine \(T_i\) bei der Eingabe von \(x\) nach \(t\) Schritten mit einer Ausgabe \(y\) hält.
Im Endeffekt also nur ein kleines Upgrade unserer Menge \(B\).
Fassen wir die Ergebnisse zusammen, kommen wir so zu unserer Antwort zum Lernziel.
Antwort zum Lernziel: Der erste Teil des Projektionssatzes ist der Grund für den Begriff „rekursiv-aufzählbar“ für eine Menge \(A\). Diese ist genau dann rekursiv-aufzählbar wenn ihre Elemente von einer totalen Funktion \(g\) aufgezählt werden können, es gilt damit \(A=Bild(g)\) und \(A\) ist r.a.
Der zweite Teil ist die Projektion, die aus den Eingabewerten \(x\) einer r.a. Menge \(A\) besteht. Da diese positiv beschieden sind, gibt es auch die zugehörige Anzahl an Schritten, die die Maschine für den positiven Bescheid brauchte. Setzen wir in den Tupeln \((x,t)\) das Element \(t\) auf Werte, die höher sind als die Schrittzahlfunktion der Maschine bei der Eingabe \(x\), so haben wir in der Menge \(B\) mehrere Tupel der Form \((x,t)\) mit festem \(x\) und variablem \(t\).
Aus diesen Elementen der Menge \(B\) bilden wir die \(x\)– und \(y\)-Achse unserer Grafik. Diese Wertekombinationen aus \(x\) und \(t\) sind entscheidbar (ich kann entscheiden ob ich zu einer positiven Eingabe \(x\) mehr als \(t\) Schritte brauche oder nicht). Das ist der Weg von einer rekursiv-aufzählbaren Menge \(A\) zu einer entscheidbaren \(B\).
Auch der Rückweg gilt: aus der Menge \(B\) mit den Elementen \((x,t)\) kann ich mir meine Eingabewerte \(x\) wieder rausholen, indem ich mich nur für das kleinste \(t\) interessiere (die Minimierungsfunktion). Damit „blende“ ich alle anderen Kombinationen mit größerem \(t\) einfach aus. Das ist die Projektion.
Merksatz: Eine Menge ist rekursiv aufzählbar wenn sie die Projektion einer entscheidbaren Menge ist.
Weiter geht es im nächsten Beitrag zum Halte- Äquivalenz- und Korrektheitsproblem, Reduzierbarkeit und Satz von Rice