Update 3: Korrektur der Beweisidee für Durchschnitt, nicht Vereinigung. Danke Phil.
Update 2: Korrektur Aufgabe aus Lernziel 3. Danke Mike.
Update: Aufgabe mit Lösung hinzugefügt um aus einem Automaten eine Regelmenge abzuleiten.
Ohne viele Worte: weiter in KE6.
Lernziel 3
Wie konstruiert man zu einem endlichen Automaten \(A\) einen regulären Ausdruck \(\alpha\) mit \(L(A)=L(\alpha)\)?
Hier kommt einiges an Schreibarbeit auf uns zu. Wie wir aus dem Beitrag zu KE5 wissen, können wir reguläre Sprachen mit einem regulären Ausdruck beschreiben. Um zu beweisen, dass eine Sprache regulär ist, muss man sie auf eine reguläre Grammatik, einen endlichen Automaten, einen regulären Ausdruck oder auf bereits bekannte reguläre Sprachen zurückführen.
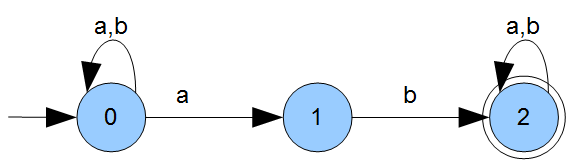
Hier haben wir einen Automaten \(A\) zu einer Sprache \(L\) bereits gegeben (die Sprache ist also als regulär bewiesen) und suchen nun auch noch einen regulären Ausdruck, der uns dieselbe Sprache beschreibt. Wir verwenden als beispiel wieder den Automaten \(A\) aus dem vorherigen Beitrag:
Beispiel: \(A=(\{a,b\},\{0,1,2\},0,2,\delta)\) mit
\(\delta=\{(1,a,1),(1,b,1),(1,a,2),(2,b,3),(3,a,3),(3,b,3)\}\)
Hier nochmal der Graph damit Ihr nicht zwischen den Beiträgen wechseln müsst:
Der Ansatz im Beweis ist ein geringfügig anderer, ich will sagen etwas formaler aus die Vorgehensweise, die ich gleich vorstelle. Das Ergebnis ist aber dasselbe. Wenn jemand eine schöne Erklärung für den formalen Beweis im Skript hat, der die folgenden zwei Formeln verwendet, immer her damit.
\({L_{ij}}^{0}=\{a\in\Sigma\mid (i,a,j)\in\delta\}\)
\({L_{ij}}^{k}={L_{ij}}^{k-1}\cup{L_{ik}}^{k-1}\cdot({L_{kk}}^{k-1})^*\cdot{L_{kj}}^{k-1}\)
Wir machen das etwas weniger formal. Die Schritte sind wie folgt:
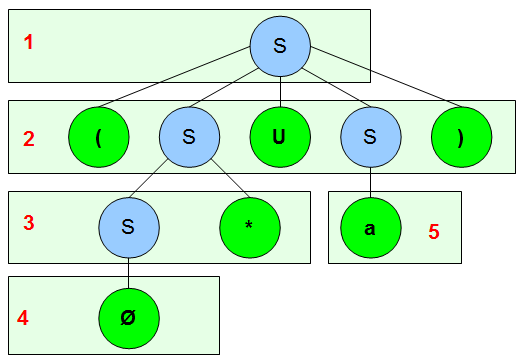
Wir führen einen neuen Startzustand \(S\) ein, der mit einem leeren Wort \(\epsilon\) bereits in unseren ehemaligen Startzustand übergeht. Ebenfalls wird ein neuer Endzustand \(E\) eingesetzt, zu dem ein Pfeil von jedem ehemaligen Endzustand gezogen wird. Auch hier wird das leere Wort als Übergang verwendet. Unser neuer Graph sieht wie folgt aus:

Wenn wir uns den Übergang von Zustand \(0\) zu Zustand \(1\) anschauen, fällt auf, dass wir in jedem Fall ein \(a\) als Abschluss der Zeichenkette brauchen um zu Zustand \(1\) zu kommen. Beliebig lange Worte, die aus \(a\) oder \(b\) zusammengesetzt sind, spielen für den Übergang aufgrund der Schleife im Zustand \(0\) keine Rolle solange das \(a\) als Suffix im Wort vorhanden ist. Das führt uns auch zu den beiden Überführungsregeln, die wir brauchen. Ein Bild sagt mehr als tausend Worte:
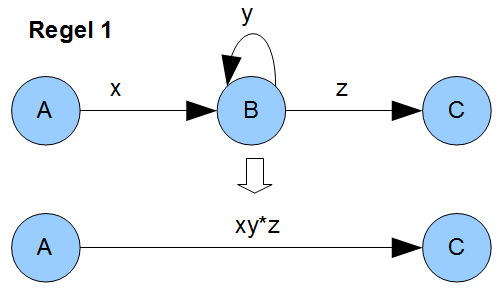
Klammern wir die Ausdrücke bei Regel 1, wird es evtl. deutlicher: \(\{x\}\cdot\{y\}^*\cdot\{z\}\) ist dann der gesuchte, reguläre Ausdruck um von Zustand \(A\) zu Zustand \(C\) zu kommen nachdem man Zustand \(B\) entfernt hat. Ein Wort, dass den regulären Ausdruck erfüllen würde, wäre z.B. \(xyyyyyyyz\) oder \(xz\). Eines, dass ihn nicht erfüllt ist \(xy\).
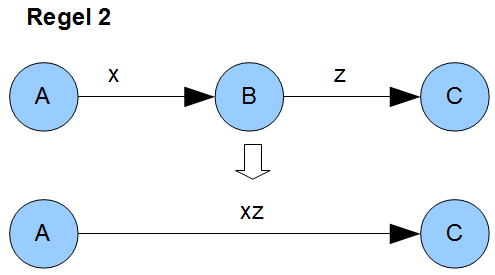
Regel 2 ist noch einfacher: Von Zustand \(A\) zu Zustand \(C\) kommt man durch die Konkatenation von \(x\) und \(z\). That’s it.
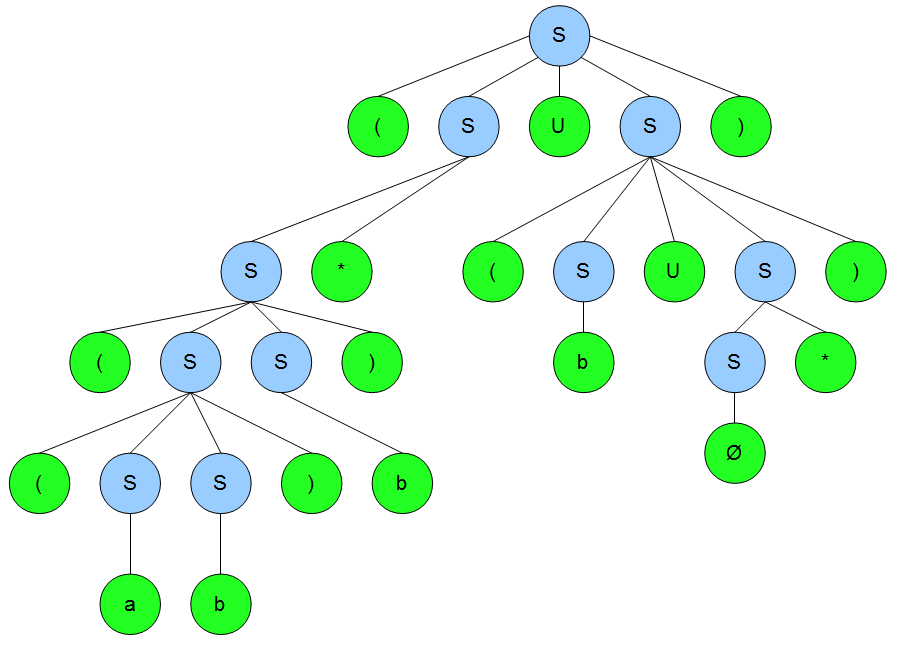
Das alles angewendet auf unseren Graphen führt uns zu folgendem:
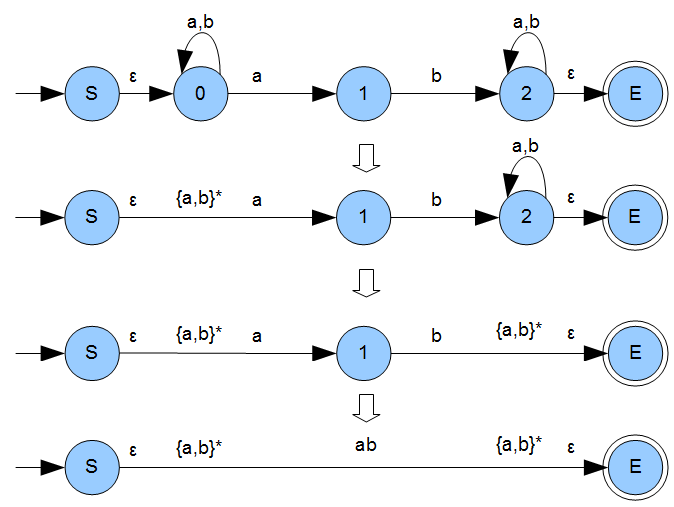
Die leeren Worte \(\epsilon\) brauchen wir nun nicht mehr und können sie streichen. Korrekt geklammert haben wir den gesuchten, regulären Ausdruck \(\alpha=\{a,b\}^{*}\cdot\{ab\}\cdot\{a,b\}^{*}\) und damit gilt: \(L(A) = L(\alpha)\). Wir können auch problemlos eine reguläre Grammatik \(G\) zum Automaten \(A\) angeben um \(L(A) = L(\alpha) = L(G)\) zu bekommen. Könnt Ihr mal selbst probieren.
Aufgabe: findet zum Automaten \(A\) die Regelmenge der passenden Grammatik
Lösung zeigen
Das Vorgehen ist hier ziemlich simpel. Wir können die Regeln praktisch direkt ableiten.
Von Zustand \(0\) kommen wir bei der Eingabe von \(a\) oder \(b\) wieder zu Zustand \(0\) und bei der Eingabe von \(a\) zu Zustand \(1\). Daraus entsteht die folgende Regelmenge:
\(0\rightarrow a0\mid b0\mid a1\)
Von Zustand \(1\) kommen wir durch Eingabe von \(b\) zu Zustand \(2\):
\(1\rightarrow b2\)
Im Zustand \(2\) verharren wir dann bei Eingabe von \(a\) oder \(b\), was uns zur letzten Regel bringt. Hier müssen wir aber auch noch aufpassen: da es unser finaler Zustand ist, gehört hier unsere \(\epsilon\)-Regel rein.
\(2\rightarrow a2\mid b2\mid\epsilon\)
Jetzt nur noch passend umbennen (Startzustand mit \(S\) ausweisen, der Rest bekommt Großbuchstaben):
\(S\rightarrow aS\mid bS\mid bA\)
\(A\rightarrow bB\)
\(B\rightarrow aB\mid bB\mid\epsilon\)
Und fertig ist die Laube.
Lernziel 4
Wie zeigt man, dass die regulären Sprache unter den in Satz 8.4.1 genannten Operationen abgeschlossen sind (Beweisidee)?
Was waren nochmal die Operationen in Satz 8.4.1? Ach ja:
- Vereinigung, Komplexprodukt, Stern
- Durchschnitt, Mengendifferenz, Komplement
- Spiegelung
Und was Abgeschlossenheit ist, wisst Ihr doch noch, oder? Die Anwendung der Operationen auf zwei Mengen der selben Klasse führt nicht aus dieser Klasse heraus. Ein einleuchtendes Beispiel sind die ganzen Zahlen \(\mathbb{Z}\), die bzgl. Subtraktion, Addition und Multiplikation abgeschlossen sind. Aber nicht bzgl. der Division: \(1:3=\frac{1}{3}\) und es gilt \(\frac{1}{3}\in\mathbb{Q}\) und \(\frac{1}{3}\notin\mathbb{Z}\).
Wie beweisen wir denn nun, dass die regulären Sprachen bzgl. der Operationen abgeschlossen sind? Fangen wir mit dem Komplement an:
Beweisidee zur Abgeschlossenheit bzgl. des Komplements
\(B\setminus A=\{x\in B\mid x\notin A\}\), wobei \(B\subseteq A\)
Was müssen wir zeigen? Es muss gelten \(L(A)=L\) und \(L(\overline{A})=\Sigma^{*}\setminus L=\overline{L}\). D.h. in \(\overline{L}\) liegen alle Worte aus \(\Sigma^{*}\), die nicht in \(L\) liegen. Das wäre dann unser Komplement.
Es werden zwei vollständige und determinierte Automaten \(A\) und \(\overline{A}\) konstruiert, die sich nur in ihren Endzuständen unterscheiden. Wir erinnern uns, dass ein Wort \(x\in\Sigma^{*}\) nur dann zu einer Sprache \(L(A)\) gehört, wenn es ausgehend vom Startzustand den Automaten \(A\) in einen Endzustand überführt.
Der Unterschied zwischen den Automaten sind nur ihre Endzustände: für Automat \(A\) sind die Endzustände in \(F\) und für Automat \(\overline{A}\) sind die Endzustände in \(Q\setminus F\), d.h. alle Zustände außer den Endzuständen \(F\) des Automaten \(A\). Die Überführungsfunktionen aus \(\delta\) bleiben erhalten. Ein kleines Beispiel um es greifbarer zu machen:
Beispiel: Sei \(A\) der Automat von oben mit \(A=(\{a,b\},\{0,1,2\},0,2,\delta)\), so wäre \(\overline{A}\) der andere Automat mit \(\overline{A}=(\{a,b\},\{0,1,2\},0,\{0,1\},\delta)\). Beachtet die Endzustände des Automaten \(\overline{A}\).
Ist also ein Wort \(x\in\Sigma^{*}\) in der Sprache \(L\), so führt es die Maschine \(A\) in den Endzustand \(2\). Ist es nicht in \(L\), so sind wir notgedrungen immer noch in Zustand \(0\) oder \(1\) unterwegs. Und das sind ja genau die Endzustände unserer Maschine \(\overline{A}\), was bedeutet, dass wenn ein Wort nicht in Sprache \(L\) ist, so ist es gezwungenermaßen in Sprache \(\overline{L}\). Die umgekehrte Richtung gilt ebenfalls, wie man sich leicht vorstellen kann.
Achtung: kontextfreie Grammatiken (Typ-2) sind nicht abgeschlossen bzgl. des Komplement!
Beweisidee zur Abgeschlossenheit bzgl. Vereinigung, Produkt und Stern:
Diese sind bereits nach der Definition der regulären Mengen ebenfalls regulär. Hier müssen wir also nichts mehr tun. Im Skript ist noch eine Beweisidee für die Vereinigung drin, aber vielleicht macht es Sinn diese hier anhand von Beispielen (aus dem Buch von Dirk W. Hoffmann) zu illustrieren.
Beispiel: Nehmen wir zunächst zwei Grammatiken (wir sind wieder bei Grammatiken, nicht mehr bei Automaten) über einem Alphabet \(\Sigma\).
\(G_1=\{\Pi_1,\Sigma,R_1,S_1\}\) (zur Erinnerung: Nonterminale, Alphabet, Regeln, Start) mit den Regeln
\(S_1\rightarrow A_1 B_1\)
\(A_1\rightarrow ab\mid aA_{1}b\)
\(B_1\rightarrow c\mid cB_1\)
\(G_2=\{\Pi_2,\Sigma,R_2,S_2\}\) mit den Regeln
\(S_2\rightarrow A_2 B_2\)
\(A_1\rightarrow a\mid aA_2\)
\(B_1\rightarrow bc\mid bB_{2}c\)
Wichtig: Wie Ihr unschwer erkennen könnt, sind die Grammatiken nur kontextfrei (Typ-2) und nicht regulär. Das ist jedoch für die Beispiele zur Vereinigung, Produkt und Stern nicht schlimm, dafür sind sie abgeschlossen. Sie sind jedoch nicht abgeschlossen für Durchschnitt und Komplement.
Wir gehen davon aus, dass die Nonterminalmengen \(\Pi_1\) und \(\Pi_2\) keine gemeinsamen Mengen haben.
Vereinigung
Wir müssen also eine Grammatik erzeugen, die uns \(L(G_1)\cup L(G_2)\) erzeugt. Dazu werden die Mengen \(\Pi_1\) und \(\Pi_2\) (Nonterminale), sowie \(R_1\) und \(R_2\) (Regeln) zu neuen Mengen zusammengefasst. Auch kümmern wir uns um das Startsymbol, welches beide Startsymbole \(S_1\) und \(S_2\) zusammenfasst. Auch müssen wir eine neue Produktion einführen und wir erhalten:
\(G_{1\cup 2}=\{\Pi_1\cup\Pi_2,\Sigma,R_1\cup R_2\cup\{S\rightarrow S_1\mid S_2\},S\}\)
Die Regelmenge sieht im Ergebnis wie folgt aus:
\(S\rightarrow S_1\mid S_2\)
\(S_1\rightarrow A_1\mid B_1\)
\(A_1\rightarrow ab\mid aA_{1}b\)
\(B_1\rightarrow c\mid cB_1\)
\(S_2\rightarrow A_{2}B_2\)
\(A_2\rightarrow a\mid aA_2\)
\(B_2\rightarrow bc\mid bB_{2}c\)
Und diese Grammatik erzeugt uns \(L(G_1)\cup L(G_2)\). Sie ist zwar nicht regulär, aber wir können sie durch Einführung von neuen Regeln und Zuständen zu einer regulären Grammatik transformieren.
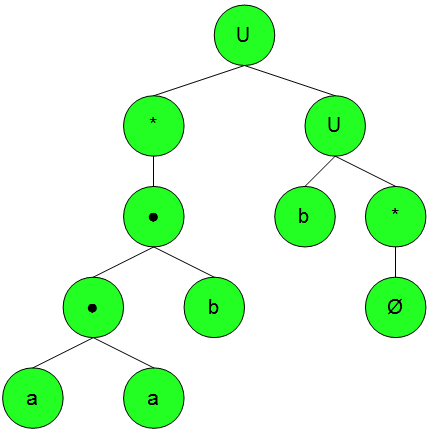
Die Beweisidee für den Durchschnitt sollten wir aber auch nicht unerwähnt lassen: Ausgehend von zwei Automaten, die unsere Mengen \(L\) und \(M\) berechnen, werden weitere Automaten für \(\overline{L}\) und \(\overline{M}\) erzeugt. Zu diesen Mengen werden zwei reguläre Ausdrücke \(\alpha\) und \(\beta\) konstruiert und diese mittels \(\cup\) zu \((\alpha\cup\beta)\) verbunden, was nichts anderes als \({L}\cap{M}\) ist.
Zu diesem Ausdruck wird eine Grammatik \(G\) konstruiert, zur Grammatik ein vollständiger Automat \(C\), welcher anschließend zu \(\overline{C}\) umgeformt wird. Alles zusammengenommen ist dann \(L(\overline{C})=\overline{L(C)}=\overline{\overline{L}\cup\overline{M}}=L\cap M\). Ich fand die Darstellung aus dem Buch von Dirk. W. Hoffmann mit dem Beispiel einfacher nachzuvollziehen.
Komplexprodukt
Hier brauchen wir eine Grammatik für \(L(G_1)L(G_2)\). Dazu werden wieder die Nonterminale und Regeln zusammengeführt und die Startsymbole durch ein neues ersetzt.
\(G_{1\cdot 2}=\{\Pi_1\cup\Pi_2,\Sigma,R_1\cup R_2\cup\{S\rightarrow S_{1}S_2\},S\}\)
Und das ist unsere neue Regelmenge:
\(S\rightarrow S_{1}S_2\)
\(S_1\rightarrow A_1B_1\)
\(A_1\rightarrow ab\mid aA_{1}b\)
\(B_1\rightarrow c\mid cB_1\)
\(S_2\rightarrow A_{2}B_2\)
\(A_2\rightarrow a\mid aA_2\)
\(B_2\rightarrow bc\mid bB_{2}c\)
Auch das sieht gut aus. Nun zum Stern.
Sternoperator: Kleene’sche Hülle
Was brauchen wir? \(L(G_1)^{*}\)! Wir brauchen hierzu einfach nur neue Ableitungsregeln, die es uns ermöglichen aus dem neuen Startsymbol eine beliebige Anzahl des ursprünglichen Startsymbols zu erzeugen. Die neue Grammatik sieht wie folgt aus:
\(G_{1^{*}}=\{\Pi_1,\Sigma,R_1\cup\{S\rightarrow\epsilon\mid SS_1\},S\}\)
Und das ist unsere neue Regelmenge:
\(S\rightarrow \epsilon\mid SS_{1}\)
\(S_1\rightarrow A_1B_1\)
\(A_1\rightarrow ab\mid aA_{1}b\)
\(B_1\rightarrow c\mid cB_1\)
Und fertig!
Weiter geht es mit dem Durchschnitt für reguläre Sprachen.
Beweisidee zur Abgeschlossenheit bzgl. des Durchschnitts:
\(B\cap A=\{x\in B\mid x\in A\}\)
Mittels der de Morgan’schen Regel gilt: \(L\cap M = \overline{\overline{L}\cup\overline{M}}\). Und die Vereinigung haben wir ja bereits in der Definition als regulär drin.
Achtung: kontextfreie Grammatiken (Typ-2) sind nicht abgeschlossen bzgl. des Durchschnitts!
Beweisidee zur Abgeschlossenheit bzgl. der Differenz
\(B\setminus A=\{x\in B\mid x\notin A\}\), wobei hier \(B\) nicht unbedingt eine Teilmenge von \(A\) sein muss.
Es gilt: \(L\setminus M=L\cap\overline{M}\)
Achtung: kontextfreie Grammatiken (Typ-2) sind nicht abgeschlossen bzgl. des Durchschnitts und somit auch nicht bzgl. der Differenz!
Beweisidee zur Abgeschlossenheit bzgl. der Spiegelung
Es muss also gelten \(L\) ist regulär \(\Rightarrow L^R = \{a_n,…,a_1\mid a_1,…,a_n\}\) ist regulär.
Ich finde hier den Beweis mittels Automat einfacher. Dazu wird einfach ein neuer Automat, der Umkehrautomat wie folgt gebildet:
- \((b,x,a)\) gdw. \((a,x,b)\) (Umkehrung der Zustandsübergänge)
- Startzustand \(q_0\) wird zum neuen Endzustand
- Neuer Startzustand mit \(\epsilon\)-Übergängen zu allen alten Endzuständen
Damit haben wir unser gespiegeltes Wort. Und da sich ansonsten nichts am Automaten geändert hat, ist die Ergebnismenge weiterhin regulär.
Antwort zum Lernziel: man zeigt die Abgeschlossenheit der regulären Sprachen bzgl. der Operationen, indem man Automaten erstellt, die die Operationen auf den beiden Mengen durchführen. Nach Definition aus dem Beitrag zu KE5 sind die regulären Sprachen, auf denen die Operationen \(\cup\), \(\cdot\) und \(*\) ausgeführt werden ebenfalls regulär. Können wir also die oben genannten Operationen damit „nachbilden“, ist uns der Nachweis gelungen (siehe Beweis zum Durchschnitt).
Lernziel 5
Welche „Probleme“ sind für reguläre Sprachen entscheidbar?
Der Abschnitt ist kurz, aber wichtig! Es gibt bestimmte Probleme auf den regulären Mengen, die entscheidbar sind. Dazu gehören:
\(x\in L_1\)? (Sprachproblem, gehört das Wort \(x\) zur Sprache \(L_1\)?)
\(L_1\subseteq L_2\)? (Inkklusionsproblem, ist \(L_1\) eine Teilmenge der Sprache \(L_2\)?)
\(L_1=L_2\)? (Äquivalenzproblem, ist die Sprache \(L_1\) äquivalent zur Sprache \(L_2\)?)
\(L_1=\emptyset\)? (Leerheitsproblem, ist die Sprache \(L_1\) leer?)
\(L_1\) endlich? (Endlichkeitsproblem, ist die Sprache \(L_1\) endlich? D.h. \(\#L_1\leq\infty\))
Für Typ-2-Sprachen können wir z.B. das Äquivalenzproblem nicht entscheiden.
Antwort zum Lernziel: Das Sprachproblem, das Inklusionsproblem, das Äquivalenzproblem, das Leerheitsproblem und das Endlichkeitsproblem sind für reguläre Sprachen entscheidbar.
Lernziel 6
Wie lautet das Pumping-Lemma für reguläre Sprachen? Wie kann man es verwenden um nachzuweisen, dass eine Sprache nicht regulär ist?
Die Definition im Skript lasse ich mal für zuletzt. Erst einmal: mit dem Pumping Lemma für reguläre Sprachen (für Typ-2-Sprachen gibt es auch eins) haben wir ein Werkzeug an der Hand, mit dem wir nachweisen können, dass eine Sprache nicht regulär ist. Das liegt an der festgelegten Struktur der Produktionen (Regeln) unserer Sprachtypen.
Sieht man sich z.B. die festgelegten Regeln für unsere regulären Sprachen an, so sieht man, dass wir in jedem Schritt ein Terminal und ein Nonterminal erzeugen, wobei das Nonterminal immer an letzter Stelle steht. Abgesehen von der Abschlussregel mit dem leeren Wort \(\epsilon\) haben wir hier ein festgelegtes Erzeugungsmuster. Das Nonterminal an letzter Stelle begrenzt die Anzahl der Regeln, die im nächsten Schritt anzuwenden sind und erlaubt uns Rückschlüsse auf die bisher erzeugten Zeichen.
Haben wir bei der Erzeugung eines Wortes mehr Schritte getan, als Nonterminale zur Verfügung stehen, so muss min. ein Nonterminal irgendwo mehrfach aufgetaucht sein. Bildlich gesprochen sind wir also über einen Zyklus im Automaten gestolpert. Denn jeder Automat zu einer regulären Sprache hat auch eine endliche Anzahl an Zuständen.
Beispiel: nehmen wir einfach \(G_1\) aus dem vorherigen Beitrag: \(G_1=(\Pi,\Sigma,R,S)\) mit \(\Pi=\{S,B,C\}\), \(\Sigma=\{a,b\}\), Startsymbol \(S\) und den Regeln \(R\):
\(S\rightarrow aB\)
\(B\rightarrow bC\)
\(C\rightarrow\epsilon\mid aB\)

Damit ist \(L(G_1)=\{ab\}*\), also alle Worte über \(ab\), d.h. z.B. \(ab\), \(ababab\) oder \(ababababa\). Hier habt Ihr auch euren Zyklus. Wir haben z.B. das Wort \(abab\): die Anzahl der Terminale ist größer als die Anzahl der Zustände im Automaten. Damit müssen wir min. einen Zyklus durchlaufen haben.
Jetzt ist der richtige Zeitpunkt für die Definition des Pumping Lemma:
Für jede reguläre Sprache \(L\) existiert ein \(j\in\mathbb{N}\), so dass sich alle Wörter \(\omega\in L\) mit \(\mid\omega\mid\geq j\) in der folgenden Form darstellen lassen:
\(\omega=uvw\) mit \(\mid v\mid\geq 1\) und \(\mid uv\mid\leq j\)
Dann ist mit \(\omega\) auch das Wort \(uv^{i}w\) für alle \(i\in\mathbb{N}_0\) enthalten.
\(j\) wird Pumping-Zahl genannt. Wenden wir die Definition von oben also auf unser Beispiel an, so hat das kleinste Wort mit einem Zyklus die Länge \(j=4\) (\(abab\)). Dann muss das Anfangsstück \(u\) mindestens die Länge \(1\) aufweisen und in Kombination mit dem Mittelteil maximal \(4\) Zeichen lang sein. Wichtig ist, dass \(j\) nicht die kleinste Länge haben muss, auf die die Kriterien zutreffen. Es genügt irgendein \(j\), das passt und man eine Zerlegung \(uvw\) für das Wort zeigen kann.
In unserem Beispiel mit dem Wort \($a ba b\) und \(j=4\) haben wir eine:
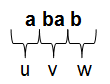
Es lässt sich der Mittelteil \(v\) also beliebig oft wiederholen und das daraus entstandene Wort ist immer noch noch in \(L\). Ist das nicht der Fall, so ist die Sprache nicht regulär. Wie man oben am Automaten sehen kann, ist die Kombination \(ba\) auch genau unser Zyklus! Wir haben in unserem Wort immer ein \(a\) am Anfang und ein \(b\) am Ende (unsere \(u\) und \(w\)), während wir den Mittelteil \(v\) beliebig oft (oder auch gar nicht) wiederholen können.
Kommen wir nun zu einer kleinen Abweichung von der obigen Grammatik.
Beispiel: \(G_2=(\Pi,\Sigma,R,S)\) mit \(\Pi=\{S,B,C\}\), \(\Sigma=\{a,b\}\), Startsymbol \(S\) und den Regeln \(R\):
\(S\rightarrow aB\)
\(B\rightarrow bC\)
\(C\rightarrow\epsilon\)
Der einzige Unterschied von \(G_1\) zu \(G_2\) ist, dass der Zustandsübergang von \(C\) keinen Zyklus mehr hat. Der Automat sieht nun wie folgt aus:

Die Sprache \(L(G_2)\) besteht also nur aus dem Wort \(ab\). Fällt euch was auf? Wir haben keinen Zyklus. Die Sprache ist trotzdem regulär. Was machen wir hier mit unserem Pumping-Lemma? Nichts! Das Pumping-Lemma ist sinnvoll für unendliche Sprachen, endliche Sprachen sind der Definition nach bereits regulär. Das heißt aber nicht, dass das Pumping-Lemma hier nicht auch funktioniert.
Nicht vergessen: wir können mit dem Pumping-Lemma nicht zeigen, dass eine Sprache regulär ist (die Erfüllung des Pumping Lemma ist nicht hinreichend), wir können aber zeigen, dass sie das nicht ist, indem wir uns eine Pumping Lemma Zahl \(j\) suchen, für Wörter, die größer sind als \(j\) die Zerlegungen durchgehen und sie prüfen. Hat keine unserer unserer Zerlegungen die gewünschte Form, so ist die Sprache nicht regulär (kontextfrei). Warum größer als \(j\)?
Ganz einfach: für eine reguläre Sprache brauchen wir nur einen endlichen Automaten anzugeben, der für jedes Wort aus der Sprache einen akzeptierenden Zustand hat.
Setzen wir \(j\) in unserem Beispiel z.B. auf \(\geq 3\), bedeutet es, dass wir für alle anderen Worte \(\leq 2\) bereits einen Automaten im Kopf haben, der für alle Wörter keiner als \(3\) akzeptierende Zustände hat. Damit ist sind bzgl. der Worte die Sprache bereits als regulär entlarvt. Fehlt uns nur noch der Beweis der Regularität aller anderen Worte der Sprache.
Tja, wie viele Worte haben wir nun mit der Länge \(\geq 3\)? Keine! Wir haben also nichts mehr zu prüfen, da eine leere Menge ist der Definition nach regulär ist. Also ist die Sprache \(L(G_2)\) nicht nur nicht nicht regulär (sorry für das komische Wortkonstrukt), sondern sogar durch die Angabe eines endlichen Automaten regulär. Das ist der Grund für die Regularität von endlichen Sprachen.
Merksatz: Endliche Sprachen sind immer regulär. Wir basteln uns hierzu einfach einen Automaten, der für jedes Wort, dass wir haben (denn die Menge unserer Worte ist endlich) einen akzeptierenden Zustand hat. Auch wenn die Länge der Worte \(2^100\) ist, und der Automat Milliarden an akzeptierenden Zuständen hat. Hauptsache sie sind endlich. That’s it.
In der Regel kennen wir das \(j\) jedoch nicht, so dass wir nur eine Sprachdefinition, wie z.B. \(L=\{(ab)^*\}\) haben und prüfen müssen ob die Sprache regulär ist. Bei Gelegenheit bringe ich hier ein paar explizite Beispiele. Bis dahin begnüge ich mich mit der Antwort zum Lernziel.
Antwort zum Lernziel: Mit dem Pumping Lemma lässt sich nachweisen, dass eine Sprache nicht regulär ist. Der Umkehrschluss gilt nicht, es gibt Sprachen, die nicht regulär sind aber das Pumping Lemma erfüllen. Dazu wird eine Pumping Lemma Zahl \(j\) gesucht und für alle Worte, die länger sind als \(j\) eine Zerlegung \(uvw\) angegeben, so dass man das Midfix \(v\) beliebig oft wiederholen kann und sich das Wort immer noch in der Sprache befindet. Tut es das nicht, so ist die Sprache nicht regulär. Wir weisen mit der Angabe von \(v\) also quasi einen Zyklus im Automaten nach, mit dem man unendliche Worte durch Wiederholung von \(v\) erstellen kann ohne die Sprache zu verlassen. Für endliche Sprachen gilt er Merksatz von oben.
Weiter geht es dann mit den letzten beiden Lernzielen im nächsten Beitrag. Fehler, Ergänzungen, Bermerkungen wie immer bitte ASAP in die Kommentare.