
Bei dem \(P-NP\)-Problem geht es um die Frage wie die beiden Komplexitätsklassen zueinander stehen. Das Skript fasst sich nur sehr kurz, was dieses Thema angeht, so dass ich beschlossen habe es hier noch einmal im Detail aufzuarbeiten.
Das \(P-NP\)-Problem gehört zu den Millenium-Problemen, d.h. es winken eine Million USD wenn es gelöst wird. Aber eine Million USD sind im Vergleich zu den Folgen, die z.B. \(P=NP\) (beide Komplexitätsklassen sind gleich) auslösen würde keine Erwähnung wert. Es wäre uns auf einen Schlag möglich für jedes Problem in \(NP\) einen effizienten Algorithmus anzugeben.
Als Beispiel nehmen wir das Faktorisierungsverfahren, auf dem sehr viele kryptographische Algorithmen (u.a. RSA oder das Verfahren von Diffie-Hellmann zum Schlüsselaustausch) basieren. Diese Algorithmen gehen davon aus, dass das Faktorisierungsproblem nicht effizient zu lösen ist. Es wäre das blanke Chaos, würde sich herausstellen, dass \(P=NP\). \(P\neq NP\) wäre hingegen nicht so schlimm.
Machen wir uns einmal klar, was \(P\) und \(NP\) denn nun wirklich sind. Dazu betrachten wir zunächst eine etwas größere Klasse.
Klassifizierung \(EXPTIME\)
In \(EXPTIME\) liegen Probleme, die auf einer deterministischen Turingmaschine in \(O(2^n)\), d.h. in exponentieller Zeit, entschieden werden können. Hier ist \(n\) die Eingabelänge.
Es ist nicht schwer zu sehen, dass man hier nur für sehr kleine Probleminstanzen effizient nach einer Lösung suchen kann. Für größere Eingabelängen \(n\) wird die Suche ungleich schwerer.
Was wäre so ein Problem, dass deterministisch in exponentieller Zeit lösbar wäre? Na klar, das Problem des Handlungsreisenden (auch TSP, travelling salesman, genannt). Der folgende Abschnitt basiert mehrheitlich auf dem Artikel aus der Wikipedia.
Beispiel TSP
Das TSP gehört zur der Klasse der Optimierungsprobleme. Bei diesem Problem geht es darum für eine gegebene Anzahl Städte und einer Entfernung zwischen diesen den kürzesten Weg für einen Rundkurs zu finden.
Diese Problem hat eine Vielzahl an Anwendungsmöglichkeiten (Logistik, Design von Mikrochips, etc.), so dass eine optimale Lösung durchaus wünschenswert erscheint.
Leider haben wir hier, in Abhängigkeit der Anzahl der zu besuchenden Punkte, nur dann eine optimale Lösung wenn wir jeden Punkt prüfen. Das Wachstum ist also exponentiell und zweifellos gehört TSP zur Klasse \(EXPTIME\), zumindest bei seinem deterministischen Lösungsansatz.
Auch wenn mittlerweile für mehrere Tausend Punkte optimale Lösungen durch heuristische und exakte Verfahren gefunden wurden, so bleibt das Problem gleich: mit wachsendem \(n\) (der Anzahl der Punkte) steigt unser Aufwand immer noch exponentiell.
Graphisch ausgedrückt (geklaut aus der Wikipedia):
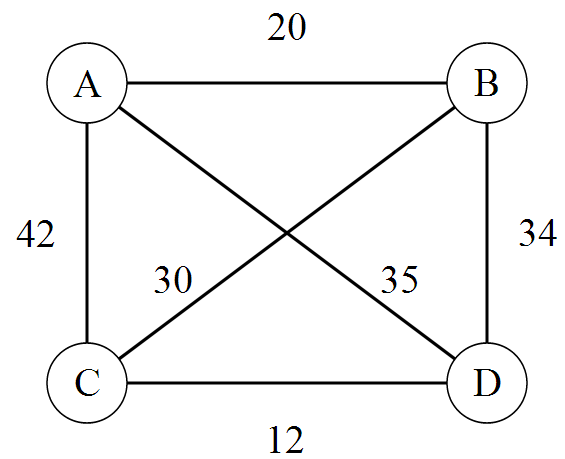
Frage: Wie ist der kürzeste Weg von \(A\) nach \(A\) über alle Punkte?
Während das bei \(4\) Punkten noch einfach ist, wird es für \(100.000\) Punkte schon deutlich schwerer.
Es sind derzeit nur effiziente, heuristische Algorithmen bekannt, die die Lösung approximieren. Z.B. der Algorithmus von Christofides, der in polynomieller Laufzeit eine Lösung approximieren kann, die maximal \(1.5\) Mal so lang ist wie die optimale Lösung.
Für exakte Lösungen gilt: jede Rundreise muss berechnet und die kürzeste ausgewählt werden. Bei \(15\) Städten haben wir \(43\) Mrd. Möglichkeiten. Hat man einen Rechner, der die Lösung für \(30\) Städte in einer Stunde berechnet, dann braucht dieser für zwei zusätzliche Städte annähernd die tausendfache Zeit; das sind mehr als \(40\) Tage.
Die Folien der RWTH Aachen zeigen eine schöne Tabelle, die ich hier Snapshotten möchte:

Das Beispiel führt vor Augen, dass uns sehr daran gelegen, dass wir Probleme nicht in Exponentialzeit lösen müssen.
Nachdem wir die Optimierungsvariante haben, kommen wir zum Bindeglied des \(TSP\) zu der Klasse \(NP\): uns geht es zunächst nicht um Optimierung, sondern um eine Entscheidung.
Die Entscheidungsvariante des \(TSP\) ist:
Gibt es eine Tour mit Kosten \({}\leq b\)?
Und hier beginnt unsere Reise: während wir hier wieder alle Wege durchprobieren und so in der Klasse der Exponentialzeit-Algorithmen landen, können wir uns das Leben deutlich einfacher machen. Aber dazu gleich mehr.
Ich gehe auf das \(TSP\) nun nicht weiter ein, da es mir nur um \(P-NP\) geht und die Ausführungen bis hierhin für diese Betrachtung ausreichen.
Kleiner Exkurs zum Schluss: Durch die Hierarchiesätze können wir z.B. zeigen, dass \(P\subsetneq EXPTIME\) ist. Damit gibt es in \(EXPTIME\) Probleme, die nicht in \(P\) liegen.
Klassifizierung \(P\)
Ein Problem in \(P\) bedeutet, dass es effizient lösbar ist. Effizient heißt: die deterministische Turingmaschine, die das Problem löst ist nach oben durch ein Polynom \(n^k\) beschränkt, wobei \(n\) die Länge der Eingabe ist. Wichtig hieran ist: \(k\) ist zwar beliebig, aber absolut unabhängig von unserer Eingabe!
Ein Beispiel für ein Problem in der Komplexitätsklasse \(P\) ist das \(PRIMES\).
Beispiel \(PRIMES\)
Hier ist die Frage ob eine Zahl \(x\) eine Primzahl ist oder nicht.
Die Antwort auf diese Frage ist ziemlich simpel: wir testen einfach aus ob alle Zahlen von \(2\) bis \(x-1\) unsere Zahl \(x\) ohne Rest teilen können. Wenn das nicht der Fall ist, ist die Zahl eine Primzahl.
Mit dem AKS-Algorithmus gibt es sogar einen, der das in Polynomzeit entscheiden kann. Damit gehört \(PRIMES\) tatsächlich zur Komplexitätsklasse \(P\).
Nach dem der Urvater der AKS-Algorithmen gefunden wurde, wurden weitere ersonnen, die die Laufzeit noch ein Stück nach unten korrigierten. Der schnellste bekannte Algorithmus aus der AKS-Familie terminiert in \(O((log\text{ }N)^{6+\varepsilon})\).
Kommen wir nun zur Komplexitätsklasse, die uns so brennend interessiert.
Klassifizierung \(NP\)
Ist ein Problem in \(NP\), so bedeutet es, dass es effizient prüfbar ist. In diesem Fall heißt effizient ebenfalls: die deterministische Turingmaschine, die prüft ob das Zertifikat \(z\) zum Problem \(X\) (ein Zertifikat ist ein Lösungsvorschlag für ein Problem), ist nach oben durch ein Polynom \(n^k\) beschränkt, wobei \(n\) die Länge der Eingabe ist.
Gemerkt, was der Unterschied zwischen \(NP\) und \(P\) ist? Es ist ein Unterschied ob wir ein Problem lösen oder „nur“ einen Lösungsvorschlag prüfen.
Was bedeutet es für unser \(TSP\)?
Beispiel \(TSP\)-Instanz
Nehmen wir unsere \(4\) Punkte aus dem obigen Beispiel und stellen uns die Frage:
Gibt es einen Weg von \(A\) nach \(A\) mit Länge \({}\leq{100}\)?
Das ist ein Entscheidungsproblem. Und hier müssten wir im schlimmsten Fall nun alle Wege durchprobieren bis wir einen Weg finden, der kürzer als/gleich \(100\) ist. Was bei vielen Punkten schon eine beträchtliche Zeit in Anspruch nehmen kann, wie wir gesehen haben. Dieses „Durchprobieren“ ist genau unser \(N\) aus \(NP\). Das Orakeln einer Lösung.
Lassen wir das Orakeln weg und geben eine Lösung vor, bleibt nur noch \(P\): die Prüfung einer gegebenen Lösung auf ihre Korrektheit. Und das können wir ziemlich zackig bewerkstelligen:
Wir prüfen die Kanten zwischen den Knoten und rechnen sie einfach zusammen:
\(A\rightarrow{C}\rightarrow{D}\rightarrow{B}\rightarrow{A}\Rightarrow{{42}\rightarrow{12}\rightarrow{34}\rightarrow{20}=108}\)
Nope, das war nichts. Versuchen wir es mit:
\(A\rightarrow{D}\rightarrow{C}\rightarrow{B}\rightarrow{A}\Rightarrow{{35}\rightarrow{12}\rightarrow{30}\rightarrow{20}=97}\)
Bingo!
Man sieht leicht, dass wir zur Prüfung einer vorgegebenen Lösung auf einer deterministischen Turingmaschine deutlich weniger Zeit benötigen als alle Wege durchzuprobieren.
Und nun holen wir uns unser \(N\) aus \(NP\), indem wir orakeln. Wir raten einfach alle Kombinationen und prüfen sie polynomiell durch unsere deterministische „Kontrollturingmaschine“.
Im Schlimmsten Fall haben wir zwar immer noch einen exponentiellen Aufwand, aber vielleicht raten wir so gut, dass die Kombination \(A\rightarrow{D}\rightarrow{C}\rightarrow{B}\rightarrow{A}\) die erste geratene Möglichkeit ist und wir schon nach dem ersten Orakeln eine Lösung gefunden haben.
Und genau das bedeutet \(NP\): raten und prüfen. Oder ganz, ganz frei interpretiert: Orakel\(N\) und \(P\)rüfen.
Codieren wir den Graphen als Turingmaschine, so hat z.B. der Zustand \(A\) drei mögliche Folgezustände (wir können zu \(B\), \(C\) oder \(D\) reisen). Es existieren also drei mögliche Zustandsübergänge, von denen wir einen wählen können. Genau hier beginnt das Raten/Orakeln, unser \(N\) aus \(NP\). Anschließend haben wir zwei Möglichkeiten zur Auswahl, usw.
So geht dann unsere \(NTM\) für das \(TSP\) vor und rät eine Rundreise. Wir brechen ab wenn die Kosten höher sind als \(b\) oder wir bei unserem Ausgangsknoten landen ohne alle Knoten besucht zu haben.
Zusammenfassend lässt sich sagen: \(NP\) bedeutet orakeln und prüfen. Und das Prüfen geschieht in maximal polynomieller Zeit.
Habt Ihr nun ein Gefühl dafür, was \(NP\) bedeutet? Gut.
Nachdem wir nun alle notwendigen Komplexitätsklassen \(EXPTIME\), \(P\) und \(NP\) besprochen haben, sollte euch klar sein wie der Zusammenhang zwischen \(P\) und \(NP\) ist.
Jetzt können wir auch die Frage stellen, die das \(P-NP\)-Problem beschreibt:
Gilt \(P=NP\) oder \(P\neq{NP}\)?
In Worten:
Sind die Klassen \(P\) und \(NP\) gleich oder nicht,
bzw.
kann jede Sprache, die nicht-deterministisch in Polynomzeit entschieden werden kann auch deterministisch in Polynomzeit entschieden werden?
Derzeit gehen alle die meisten von letzterem aus. Die Folgen wären, wie gesagt, übersichtlich wenn das stimmt. Dafür müssten wir nur zeigen, dass es in \(NP\) Probleme gibt, die definitiv nicht deterministisch polynomiell lösbar, also nicht in \(P\) sind.
Graphisch aufgearbeitet sieht die hier beleuchtete, problematische Beziehung zwischen \(P\) und \(NP\) so aus:
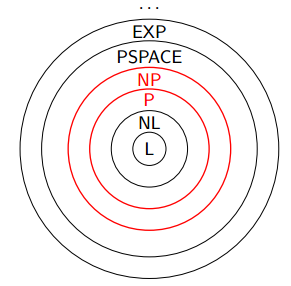
Entnommen aus den Folien der TUM.
Und welche Möglichkeiten haben wir nun um \(P=NP\) oder \(P\neq{NP}\) zu beweisen?
- Konstruktiver Beweis
Wir finden einen polynomiellen Algorithmus, der ein \(NP\)-Vollständiges Problem polynomiell löst. Die Vollständigkeit ist wichtig, so dass wir diesen Algorithmus auch auf alle anderen aus \(NP\) reduzieren können müssen um die Klasse komplett abzudecken.
Schaffen wir es also z.B. \(TSP\) deterministisch polynomiell zu lösen, haben wir – da \(TSP\) eben \(NP\)-vollständig ist, nichts geringeres als \(P=NP\) bewiesen.
- Nicht-konstruktiver Beweis
Nicht-konstruktiv bedeutet, dass man keine konkrete Lösung angibt, aber eindeutig auf die Existenz einer Lösung schließen kann.
Man kann hier auch einen indirekten Beweis führen, indem man annimmt, es gäbe keine Lösung und diesen Satz zu einem Widerspruch führt. Daraus kann man dann schließen, dass es eine Lösung geben muss. Aber welche das ist, wird nicht genannt.
Also an die Arbeit 😉
Ich hoffe, ich konnte euch die Beziehung zwischen \(P\) und \(NP\) in diesem Beitrag etwas deutlicher machen.
Wie immer: Bei Ungenauigkeiten, ab in die Kommentare.
