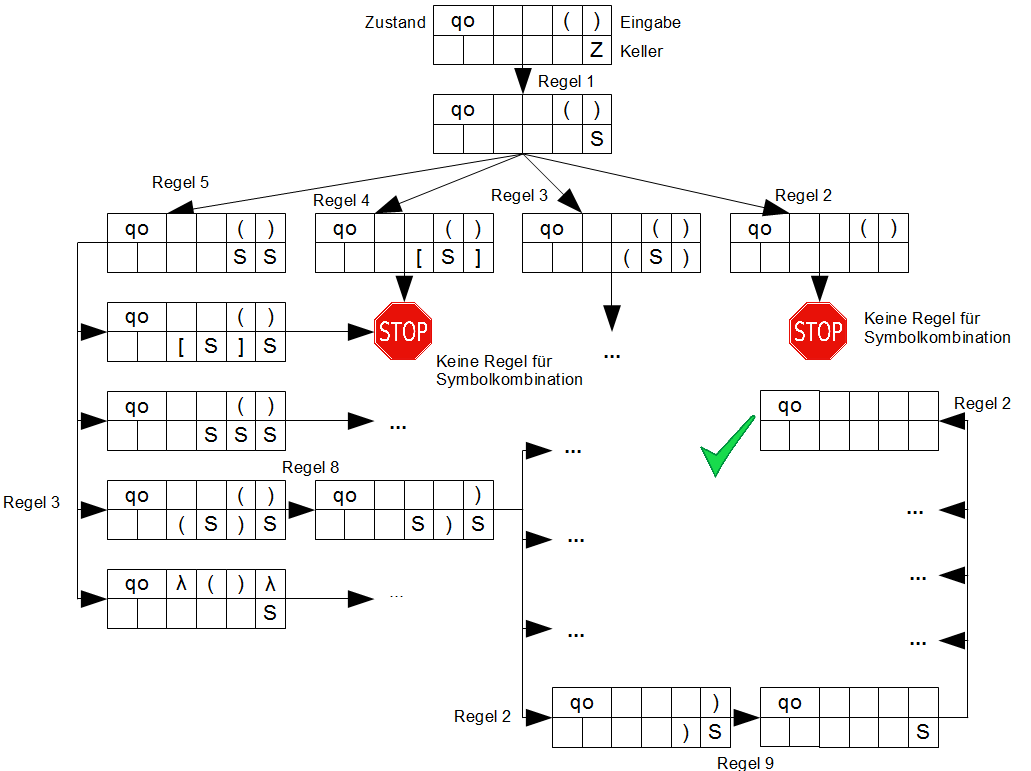
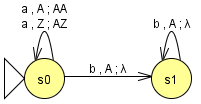
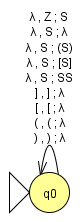Update: Fehler im Automaten behoben.
Letzter Beitrag zum Thema… ich tippe besonders langsam, versprochen 😉
Lernziel 5
Was sind determinierte Kellerautomaten?
Wir könnten zwar mit nichtdeterministischen Kellerautomaten leben und würden es sogar. Aber es gibt da ein Problem: wir können sie technisch nicht realisieren.
Den determinierten Kellerautomaten hatten wir im vorherigen Beitrag auch bereits definiert. Uns interessiert deshalb nicht was sie sind, sondern vielmehr wie sie sich von nichtdeterministischen Kellerautomaten unterscheiden und was das für Auswirkungen auf die erkannte Sprachklasse hat.
Eine echte Teilmenge der von nichtdeterminierten Kellerautomaten erkannten, kontextfreien Sprachen ist die deterministische kontextfreie Sprache:
Deterministisch kontextfrei
Eine Sprache ist deterministisch kontextfrei wenn es einen determinierten Kellerautomaten gibt, der sie erkennt.
Das Erkennen bedeutet folgendes:
Wenn \(L\subseteq\Sigma^{*}\) eine deterministisch kontextfreie Sprache ist, dann gibt es einen Kellerautomaten \(A=(\Sigma,\Gamma,\$,Q,q_0,\{q_{+}\},\delta)\) mit einem Zustand \(q_{-}\in Q\), so dass für alle Worte \(\omega\in\Sigma\) gilt:
\(\omega\in L\Leftrightarrow (q_0,\omega\$,\$)\vdash^{*}(q_{+},\$,\epsilon)\)Das Wort \(\omega\) ist Teil der deterministisch kontextfreien Sprache wenn es eine Überführungsfolge im Automaten \(A\) gibt, die ausgehend vom Anfangszustand in einen akzeptierenden Endzustand mündet und die Eingabe zu Ende gelesen wurde, wobei der Keller leer ist.
\(\omega\notin L\Leftrightarrow (q_0,\omega\$,\$)\vdash^{*}(q_{-},\$,\epsilon)\)Das Wort \(\omega\) ist nicht Teil der deterministisch kontextfreien Sprache wenn es eine Überführungsfolge im Automaten \(A\) gibt, die ausgehend vom Anfangszustand in einen nicht-akzeptierenden Endzustand mündet und die Eingabe zu Ende gelesen wurde, wobei der Keller leer ist.
Sie ist zudem auch noch eindeutig:
Jede deterministisch erkannte Sprache ist eindeutig*.
* erinnert Ihr euch noch an die Eindeutigkeit? Fall nicht: jedes abgeleitete Wort einer eindeutigen Sprache/Grammatik hat nur einen einzigen Ableitungsbaum.
Wir zeigen gleich, dass die deterministischen Automaten weniger leistungsfähig sind. Folgende Überlegungen sind notwendig:
1. ein deterministischer Kellerautomat akzeptiert nur Worte, die er zu Ende liest. Wir müssen daher unseren deterministischen Automaten entsprechen ummodellieren und die Szenarien vermeiden, wo der Automat nicht weiterlesen kann:
a) Keller leer bevor Eingabe zu Ende.
Lösung: neues Keller-Leerheits-Zeichen, dass nie gelöscht wird.
b) keine Folgekonfiguration für aktuelle Konfiguration vorhanden
Lösung: Vervollständigen von \(\delta\), so dass wir zu jeder Möglichkeit einen Folgezustand haben
c) das Erreichen eines Zyklus, wo der Kopf nicht bewegt wird
Lösung: Erkennen und vermeiden des Zyklus.
2. Wir haben einen ausgezeichneten, positiven Endzustand: entweder er akzeptiert das Wort und wir landen in \(q_{+}\) oder nicht und wir landen in \(q_{-}\in Q\).
Mit der Vorarbeit aus dem letzten Beitrag, ist es nicht schwer diese weiteren Einschränkungen nachzuvollziehen.
Der Beweis für die Komplementbildung gelingt durch simples Vertauschen der Zustände \(q_{+}\) und \(q_{-}\), so dass wir diese Eigenschaft zusammenfasen können:
Sei \(L\subseteq\Sigma^{*}\) deterministisch kontextfrei, so ist es auch \(\Sigma^{*}\setminus L\).
Antwort zum Lernziel: Kellerautomaten (PDAs) sind endliche Automaten, die durch einen Kellerspeicher erweitert wurden. Bei einem Kellerautomaten wird ein Wort dann erkannt wenn der Keller leer ist oder der Automat in einem Endzustand landet (oder beides gleichzeitig).
Für einen determinierten Kellerautomaten gilt zudem, dass es für jedes Eingabezeichen und jedes oberste Kellerzeichen nur einen Zustandsübergang gibt, so dass der Kellerautomat den Berechnungsweg nicht zufällig wählen kann. Ist das nicht der Fall und gibt es zu einem Eingabezeichen und einem obersten Kellerzeichen mehrere mögliche Folgezustände, so ist der Kellerautomat nichtdeterministisch.
Für eine deterministisch kontextfreie Sprache \(L\) bedeutet es, dass wir in jedem Fall für ein Wort \(\omega\in L\) nach endlich vielen Schritten die Endkonfiguration \((q_{+},\$,\epsilon)\) (ausgewiesener Endzustand, Ende der Eingabe, leerer Keller) oder für ein Wort \(\omega\notin L\) \((q_{-},\$,\epsilon)\) (beliebiger Zustand aus \(Q\), Ende der Eingabe, leerer Keller) erreichen.
Lernziel 6
Ist jede kontextfreie Sprache deterministisch? Mit Begründung!
Ein (für mich) etwas verständlicheres Beispiel habe ich in den Folien der HU-Berlin gefunden und würde das hier gerne anbringen. Nehmen wir zwei deterministisch kontextfreie Sprachen (DCFL), die von einem determinierten Automaten erkannt wird, z.B.
\(L_1=\{a^i b^j c^k\mid i\neq j\}\in DCFL\) sowie
\(L_2=\{a^i b^j c^k\mid j\neq k\}\in DCFL\).
Beide Sprachen sind deterministisch kontextfrei. Wir können also einen deterministischen Kellerautomaten angeben, der sie erkennt.
Um \(L_1\) zu entscheiden, können wir uns z.B. darauf beschränken die \(a’s\) einzulesen, \(A’s\) in den Keller zu schreiben und anschließend die \(b’s\) einzulesen und die \(A’s\) aus dem Keller zu entfernen. Es sind drei Fälle zu unterscheiden:
1. Gab es weniger \(a’s\) als \(b’s\), so haben wir noch \(b’s\) auf dem Eingabeband, während der Keller bereits leer ist und alles ist gut.
2. Gab es mehr \(a’s\) als \(b’s\), so haben wir keine \(b’s\) auf dem Eingabeband, während noch \(A’s\) im Keller sind und alles ist immernoch gut.
3. Gab es die gleiche Anzahl \(a’s\) und \(b’s\), so haben wir einen leeren Keller just in dem Moment, wo wir keine \(b’s\) auf dem Eingabeband haben und das Wort wird abgelehnt.
Das gleiche Verfahren klappt auch mit \(L_2\) (nur mit \(b’s\) und \(c’s\) statt mit \(a’s\) und \(b’s\)).
Schauen wir uns doch eine weitere Sprache an:
\(L_1\cup L_2 = \{a^i b^j c^k\mid i\neq j\) oder \(j\neq k\}\in CFL\setminus DCFL\).
Wie man sieht, ist das eine Vereinigung der beiden Sprachen \(L_1\) und \(L_2\). Um das etwas anschaulicher zu machen, schauen wir uns die Mengen doch einmal mit \(1\leq i,j,k\leq 2\) an:
\(L2_1=\{abbc,abbcc,aabc,aabcc\}\)
\(L2_2=\{abcc,abbc,aabcc,aabbc\}\)
\(L2_1\cup L2_2 = \{abbc,abbcc,aabc,aabcc,abcc,aabbc\}\)
Während wir für für \(L2_1, L2_2\) und die Vereinigung der beiden Sprachen \(L2_1\cup L2_2\) sogar einen endlichen Automaten angeben können, der sie erkennt (wir erinnern uns: das ist genau der Grund warum alle endlichen Sprachen sogar regulär sind, ein akzeptierender Zustand pro Wort reicht im endlichen Automaten aus um die Sprachen zu erkennen), gelingt es uns bei \(i,i,k\in\mathbb{N}\) nur für \(L_1\) sowie \(L_2\) einen Kellerautomaten anzugeben, der die Sprache erkennt (wir müssen die Anzahl der Buchstaben beobachen können und können das nur mindestens mit einem Kellerautomaten. Mindestens weil Turingmaschinen als stärkstes Berechnungsmodell selbstverständlich auch gehen, denn sie können ja selbst Typ-0-Sprachen erkennen).
Weit mehr Probleme macht uns die Vereinigung! Das Problem mit ihr ist: sie ist zwar kontextfrei, aber nicht deterministisch kontextfrei. Denn dafür können wir keine deterministische Kellermaschine angeben, sie sie erkennt.
Woran liegt das? Wie wir oben gesehen haben, beobachten wir mit dem Keller nur eine Variable (die Anzahl unserer ersten, eingelesenen Buchstaben) und können so eine andere abhängig von dieser entscheiden. Das ist bei den Sprachen \(L_1\) und \(L_2\) ja kein Problem. Bei \(L_1\cup L_2\) haben wir jedoch drei Variablen, die von einander abhängig sind. Denn wir müssen \(j\) in Abhängigkeit von \(i\) und \(k\) in Abhängigkeit von \(j\) prüfen. Das war’s also mit dem Determinismus, denn wir haben mehrere Wege, die wir beschreiten müssen um am Ende einen zu finden, der funktioniert.
Die kontextfreie Grammatik für \(L_1\cup L_2\) ist:
\(S\rightarrow{DC \mid AE \mid B}\)
\(D\rightarrow{F\mid G}\) \(F\rightarrow{aF \mid aFb \mid a}\) \(G\rightarrow{Gb \mid aGb\mid b}\) \(C\rightarrow{cC\mid\epsilon}\)\(A\rightarrow{aA\mid\epsilon}\)
\(E\rightarrow{H\mid I}\) \(H\rightarrow{bH\mid bHc\mid b}\) \(I\rightarrow{Ic \mid bIc \mid c}\)\(B\rightarrow{J \mid K}\)
\(J\rightarrow{aJ\mid aJc\mid aL}\) \(K\rightarrow{Kc\mid aKc\mid Lc}\) \(L\rightarrow{bL\mid\epsilon}\)Und daraus können wir den zugehörigen Automaten nach dem Schema aus dem vorherigen Beitrag bauen:

Download: AiBjCk_NPDA_JFLAP-Datei
Damit haben wir auch eine wesentliche Aussage für das nächste Lernziel herausgearbeitet: dass wir keinen deterministischen Automaten für \(L_1\cup L_2\) angeben können liegt daran, das die deterministisch kontextfreien Sprachen zwar abgeschlossen sind bzgl. Schnitt und Komplement, aber nicht gegen Vereinigung, Durchschnitt, Spiegelung und Konkatenation! Und das obere Beispiel war die Vereinigung. Beispiele für Durchschnitt, Spiegelung und Konkatenation überlasse ich erstmal euch 😉
Zusammengefasst: Wir haben mit dem deterministischen Kellerautomaten, welche die Sprache erkennt, tatsächlich eine Beschneidung der Möglichkeiten, die uns ein nichtdeterministischer Kellerautomat bietet: wir können nicht mehr zwischen Berechnungspfaden wählen und sind an unsere Wahl „gebunden“. War sie falsch, so landen wir in einer Sackgasse und damit war es das. Bei einem nichtdeterministischen Automaten haben wir währenddessen (durch mehrere Folgekonfigurationen für eine Konfiguration) bereits andere Wege parallel beschritten, wo uns einer (wenn wir einen korrekten Automaten angegeben haben) schon zur Lösung führen wird. War eine Berechnung falsch, so landen wir auf diesem einen Weg in einer Sackgasse und … es ist uns egal. Wir haben ja noch genug andere Wege, die wir parallel beschreiten.
Hauptsache wir können beweisen, dass min. einer dieser Wege zu einem Ergebnis führt und entscheidet ob ein Wort sich in der Sprache befindet. Tut es das nicht, kann der nichtdeterministische Automat von uns aus solange weiterrechnen, bis er schwarz wird.
Ein Blick aus einer anderen Brille: Um bei der Sprache \(L_1\cup L_2\) entscheiden zu können ob ein Wort tatsächlich zur Sprache gehört oder nicht, ist der Algorithmus wirklich einfach: Wir zählen die \(a’s\), \(b’s\) und \(c’s\), speichern die Anzahl auf dem Hilfsband und vergleichen die drei Variablen nachdem wir die Eingabe vollständig eingelesen haben miteinander. Ihr habt sicher schon eine TM im Kopf, die das macht. Während wir das also mit einer DTM problemlos machen können, schaffen wir das mit einem PDA durch die Einschränkungen leider nicht.
Antwort zum Lernziel: Nicht jede kontextfreie Sprache ist deterministisch. Es gibt kontextfreie Sprachen, die aufgrund ihrer Struktur nicht von einem PDA erkannt werden können weil ihr Aufbau von mehreren Variablen abhängt, diese jedoch nicht durch einen einzigen Kellerspeicher deterministisch abgebildet werden können. Erst durch das Beschreiten mehrerer Berechnungspfade ist es möglich auch mehrere Variablen in die Betrachtung einzubeziehen und aus der so generierten Vielzahl an Pfaden die Aussage zu treffen, dass einer in jedem Fall zum Ziel führt wenn das Wort sich in der Sprache befindet.
Eine solche kontextfreie, aber nicht deterministische Sprache lässt sich durch Vereinigung, Konkatenation, Durchschnitt oder Spiegelung einer oder mit mehreren deterministisch kontextfreien Sprachen erzeugen, da die Sprachklasse der deterministisch kontextfreien Sprachen nicht abgeschlossen gegen diese Operationen ist.
Lernziel 7
Sind die kontextfreien bzw. deterministisch kontextfreien Sprachen abgeschlossen unter Vereinigung, Durchschnitt, Komplement und Schnitt mit regulären Mengen?
Was soll ich hier schreiben? Reicht die Tabelle aus dem Skript? 😉 Ihr solltet euch noch einmal vor Augen führen, wie die Sprachklassen zusammenhängen und die Beziehungen zwischen Unter- und Oberklasse sind. Dann wird euch auch deutlich warum diese gegen gewisse Operationen nicht abgeschlossen sein können. Vielleicht schreibe ich später noch ein paar Sätze dazu, aber bis dahin:
Antwort zum Lernziel:
| kontextfrei | deterministisch | |
| Vereinigung | + | – |
| Durchschnitt | – | – |
| Komplement | – | + |
| Konkatenation | + | – |
| Stern | + | – |
| Schnitt mit regulären Mengen | + | + |
Lernziel 8
Welche der folgenden Probleme sind für kontextfreie Grammatiken entscheidbar/unentscheidbar? Wortproblem, Endlichkeitsproblem, Leerheitsproblem?
Hier sollten wir einige Probleme auf den Mengen entscheiden können, diese sind:
- Wortproblem: ob sich ein Wort \(\omega\) in der Sprache \(L\) befindet (oder nicht).
- Inklusion: ob die Worte einer Sprache \(L_1\) in einer anderen Sprache\(L_2\) enthalten sind
- Äquivalenz: ob die Sprache \(L_1\) die gleiche Sprache wie \(L_2\) ist.
- Leerheit: ob die Sprache leer ist, d.h. wir können mir der Grammatik, die die Sprache erzeugt keine Wörter erzeugen. Achtung: jede leere Sprache ist regulär.
- Endlichkeit: ob die Sprache endlich ist (endliche Sprache = reguläre Sprache = endlicher Automat)
- Universalität: ob die Sprache alle Kombinationen der Elemente aus dem Alphabet \(\Sigma\) umfasst
- Eindeutigkeit: ob es für ein Wort nur einen Ableitungsbaum gibt.
- Determiniertheit: es gibt einen deterministischen Kellerautomaten, der entscheidet ob \(\omega\) zur Sprache gehört oder nicht.
Antwort zum Lernziel:
| kontextfrei | deterministisch | |
| Wortproblem | + | + |
| Inklusion | – | – |
| Äquivalenz | – | + |
| Leerheit | + | + |
| Endlichkeit | + | + |
| Universalität | – | + |
| Eindeutigkeit | – | + |
| Determiniertheit | – | + |
Damit haben wir auch die letzte Kurseinheit durch. Hoffentlich konntet Ihr etwas mit den Zusammenfassungen anfangen und es haben sich keine Fehler eingeschlichen. Wenn doch: ab damit in die Kommentare!